💣Synthesis Sound Effects from Vocal Imitations💣
not Limited to the Linguistic Pronunciations
Author
Riki Takizawa1,
Shigeyuki Hirai2
1: Department of Frontier Informatics, Graduate School of Kyoto Sangyo University, Japan.
2: Faculty of Information Science and Engineering ,Kyoto Sangyo University, Japan.
Abstract
We proposed a method to synthesize sound effects with controlling nuances by representing utterances of onomatopoeia which don't depend on linguistic pronunciations. Figure 1 shows the schematic image of our proposed method, Voice-to-SE. In this method, we utilize Transformer for the conversion of sound effects from utterances.

Learn More...
Result1
Mel-spec |
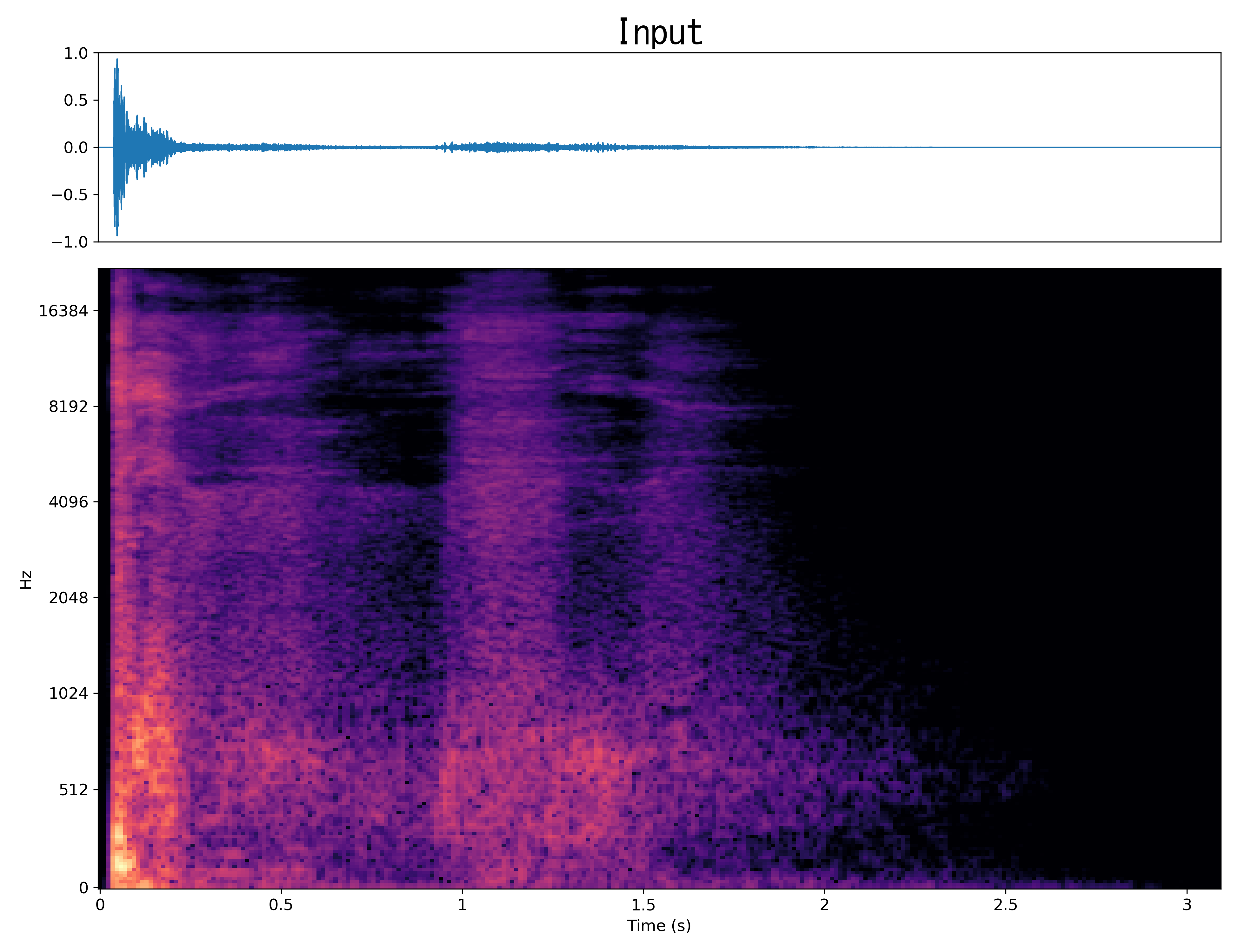 |
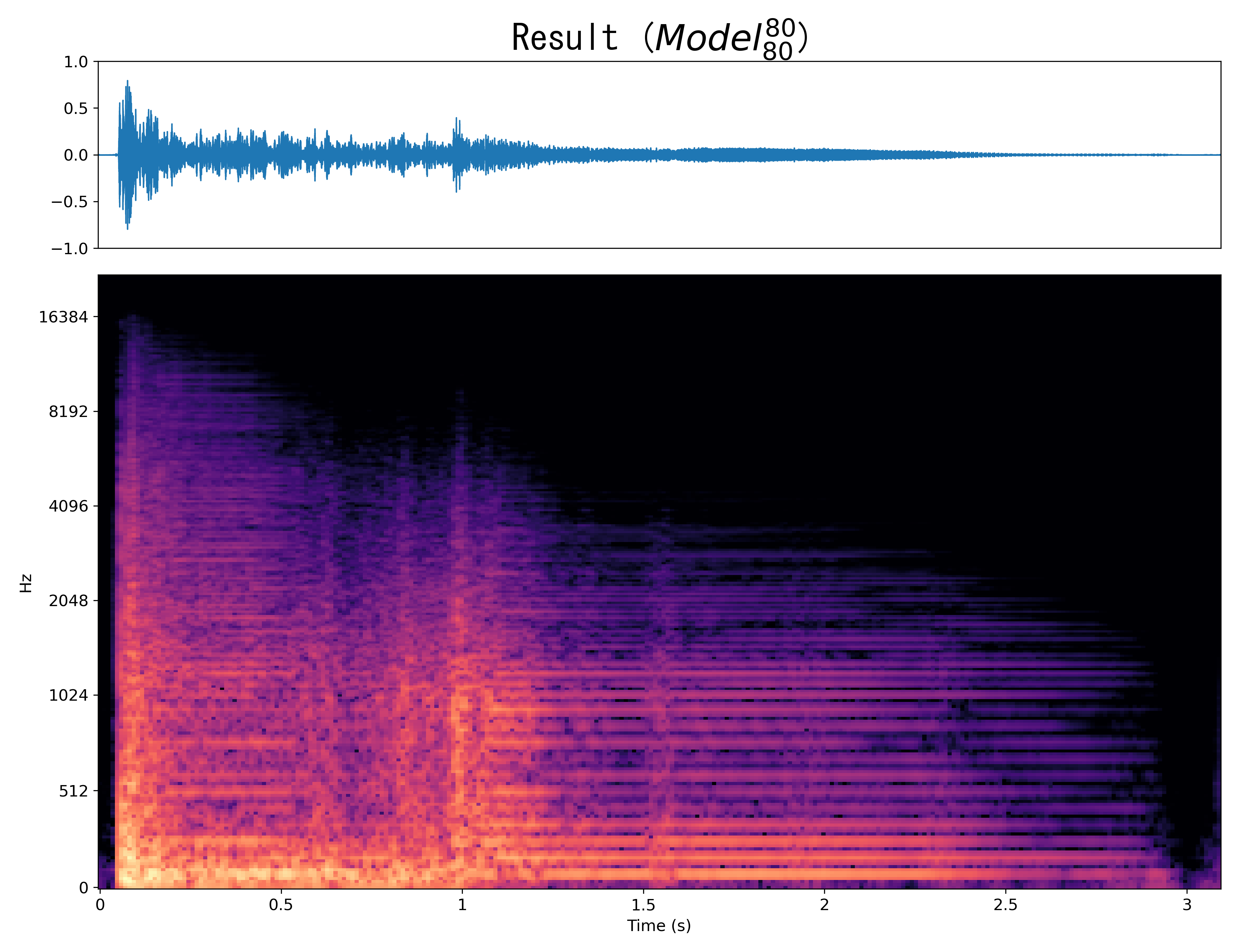 |
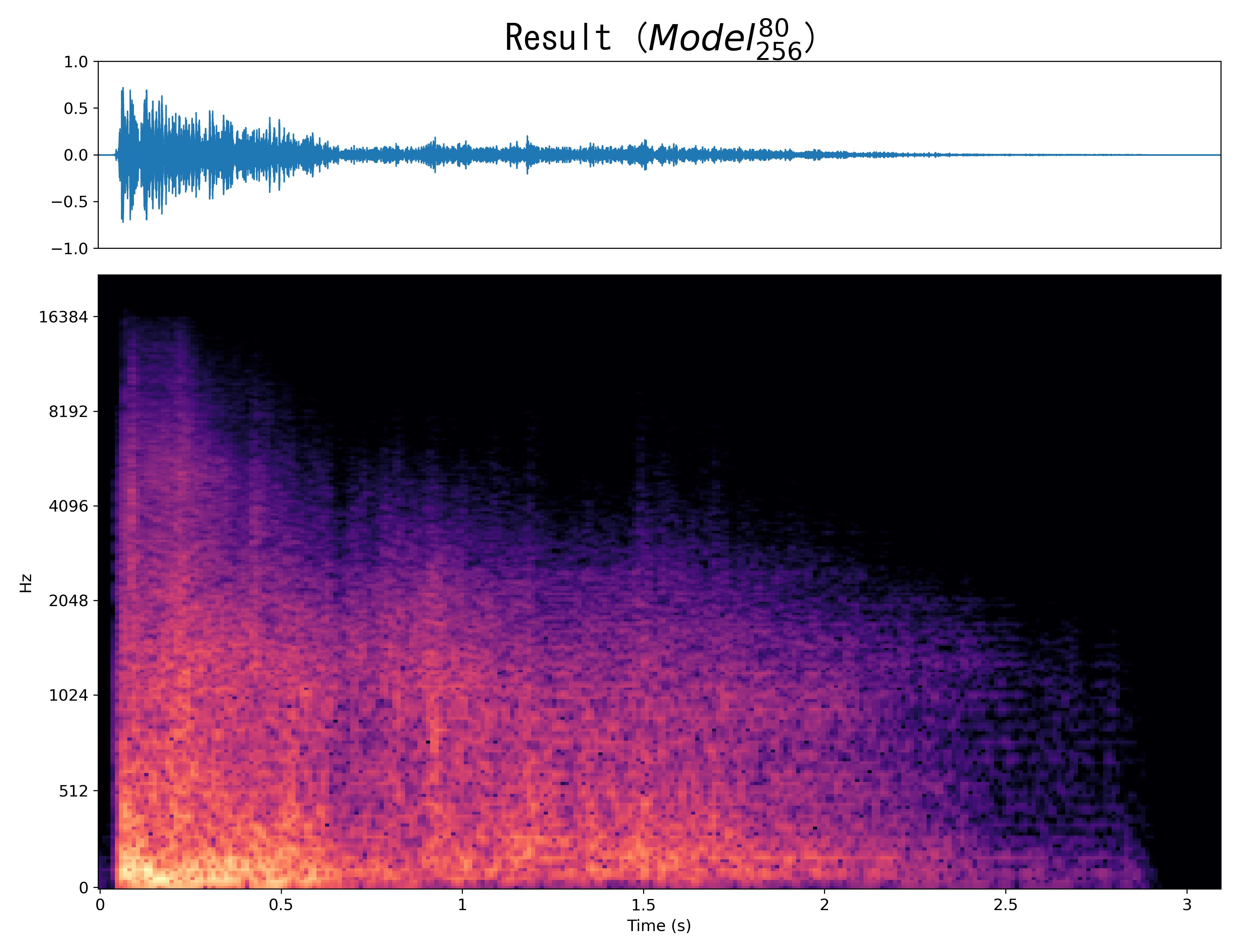 |
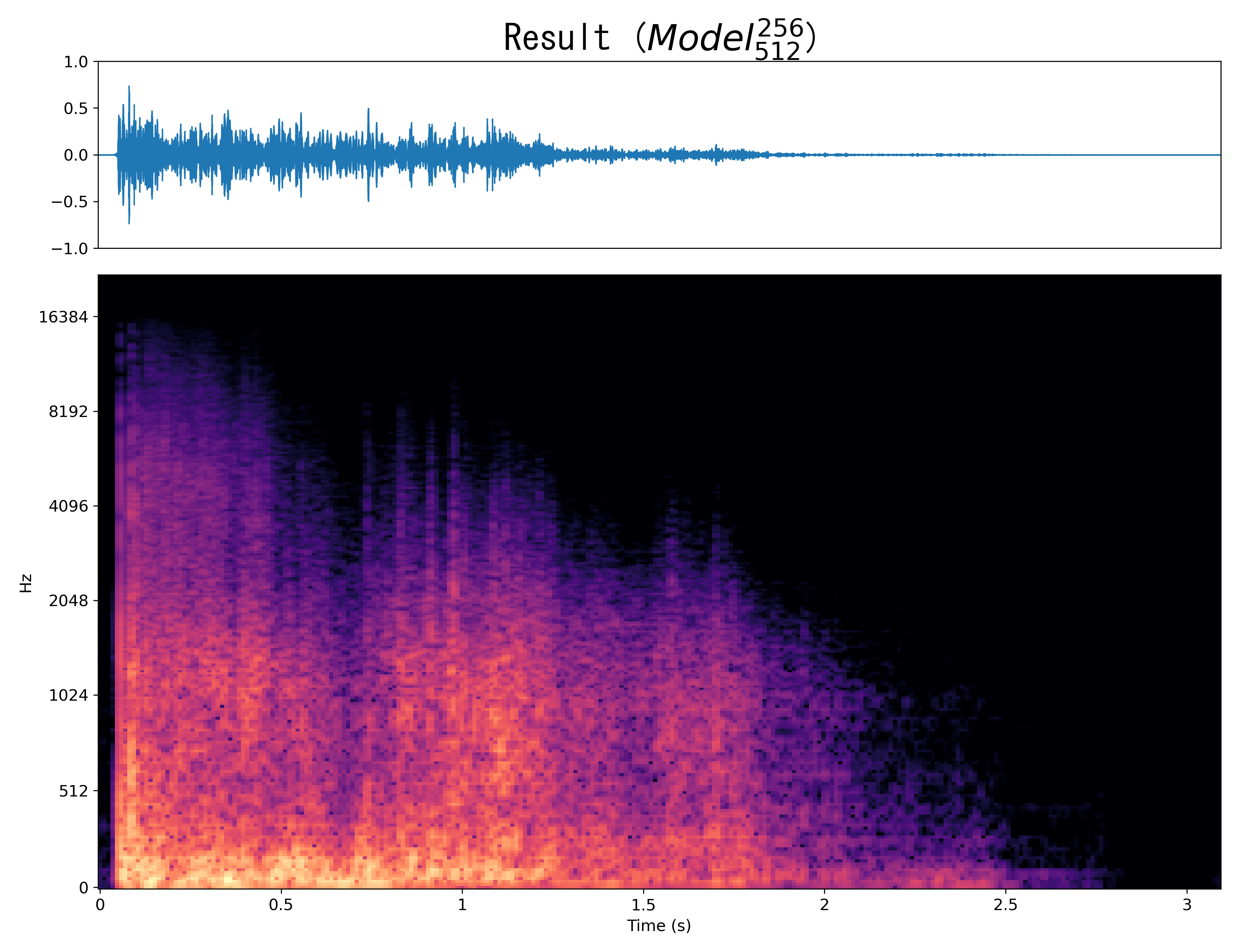 |
|---|---|---|---|---|
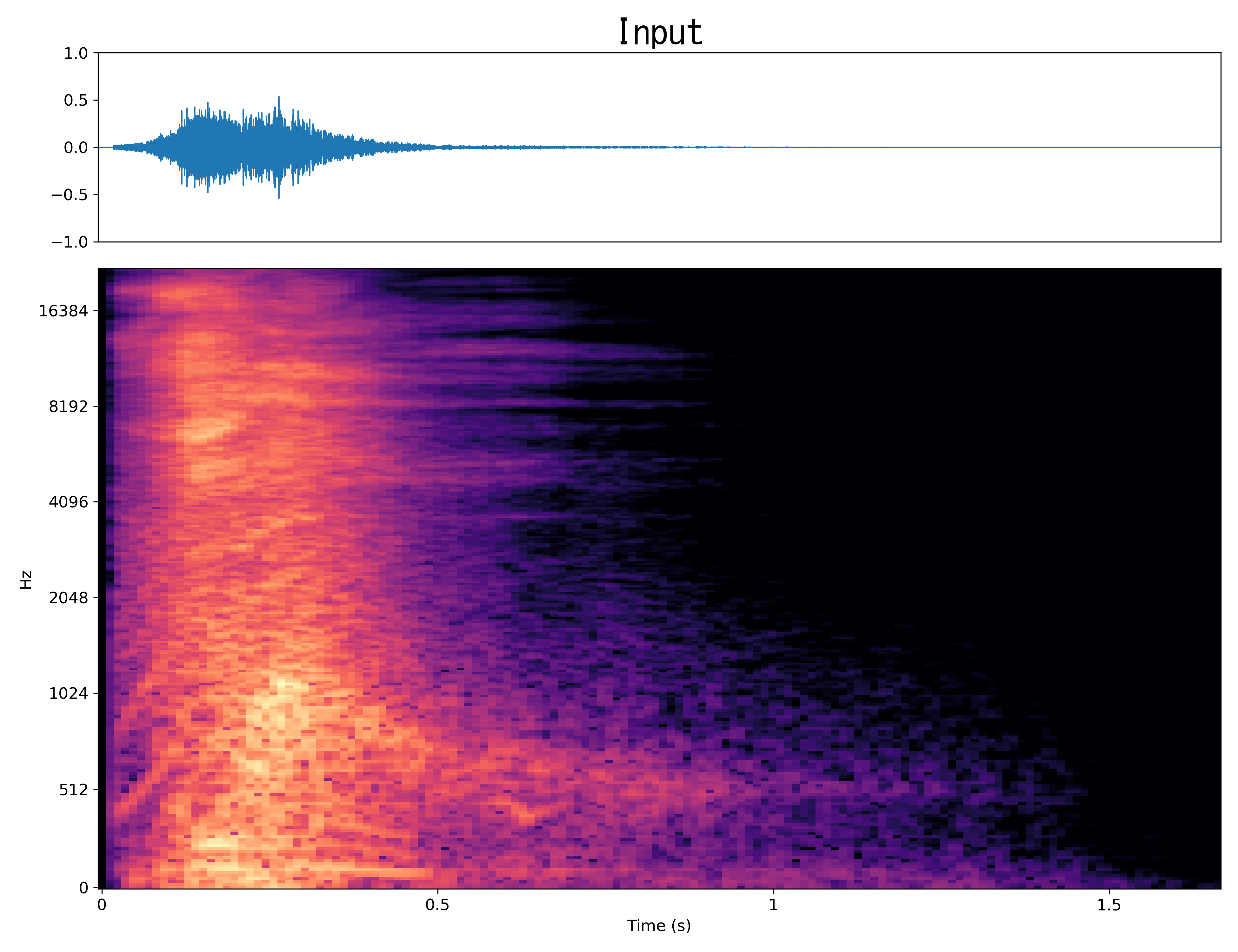
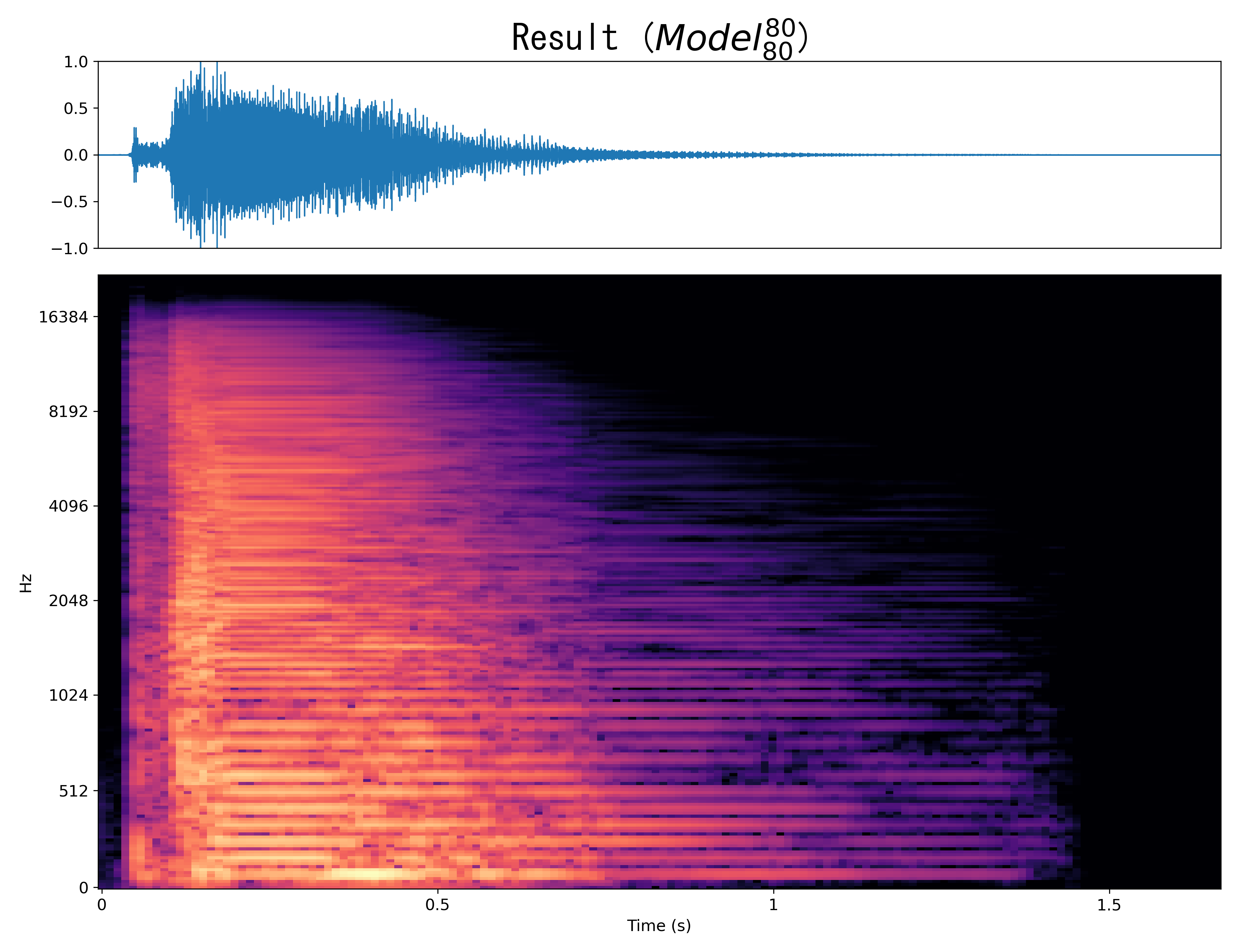
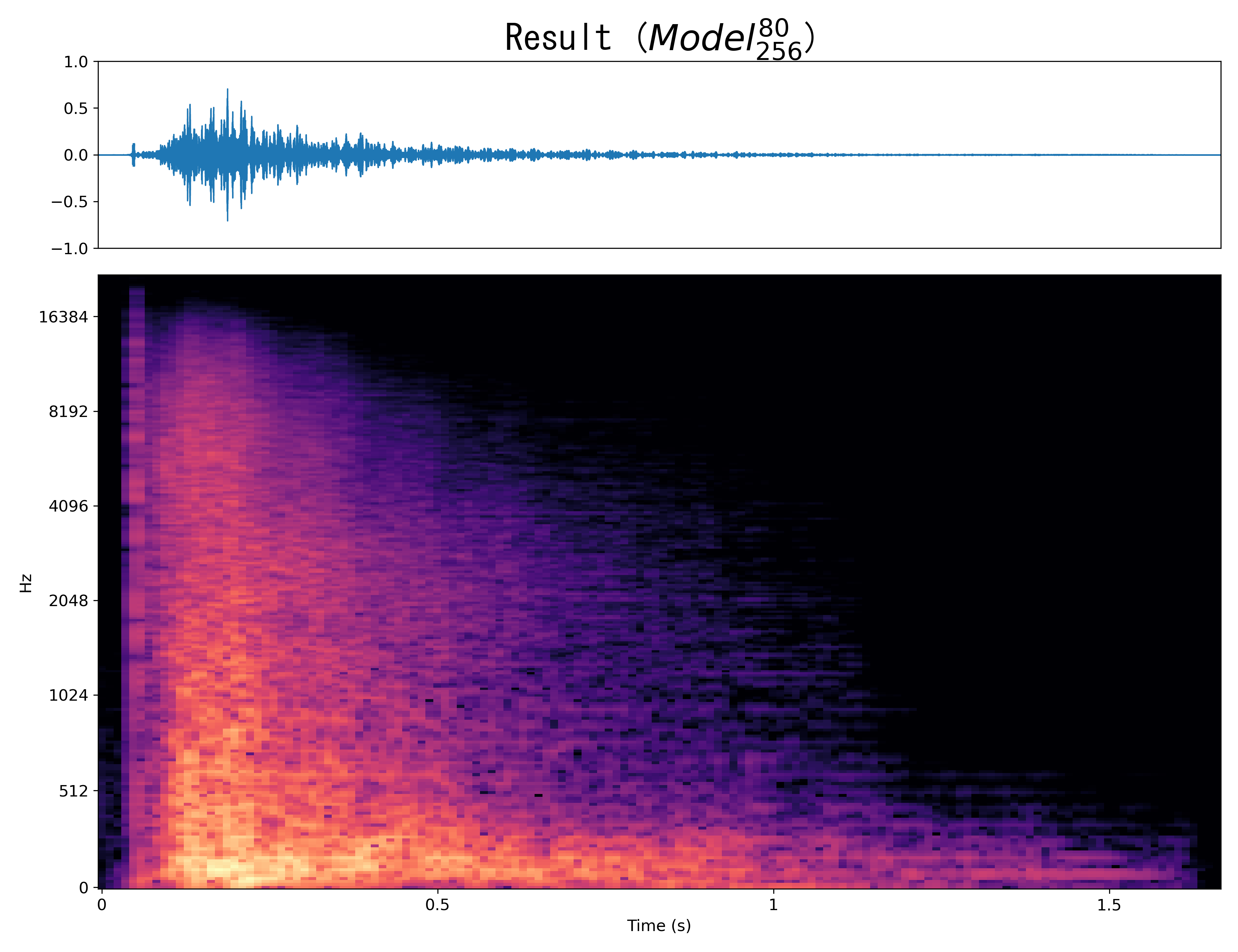
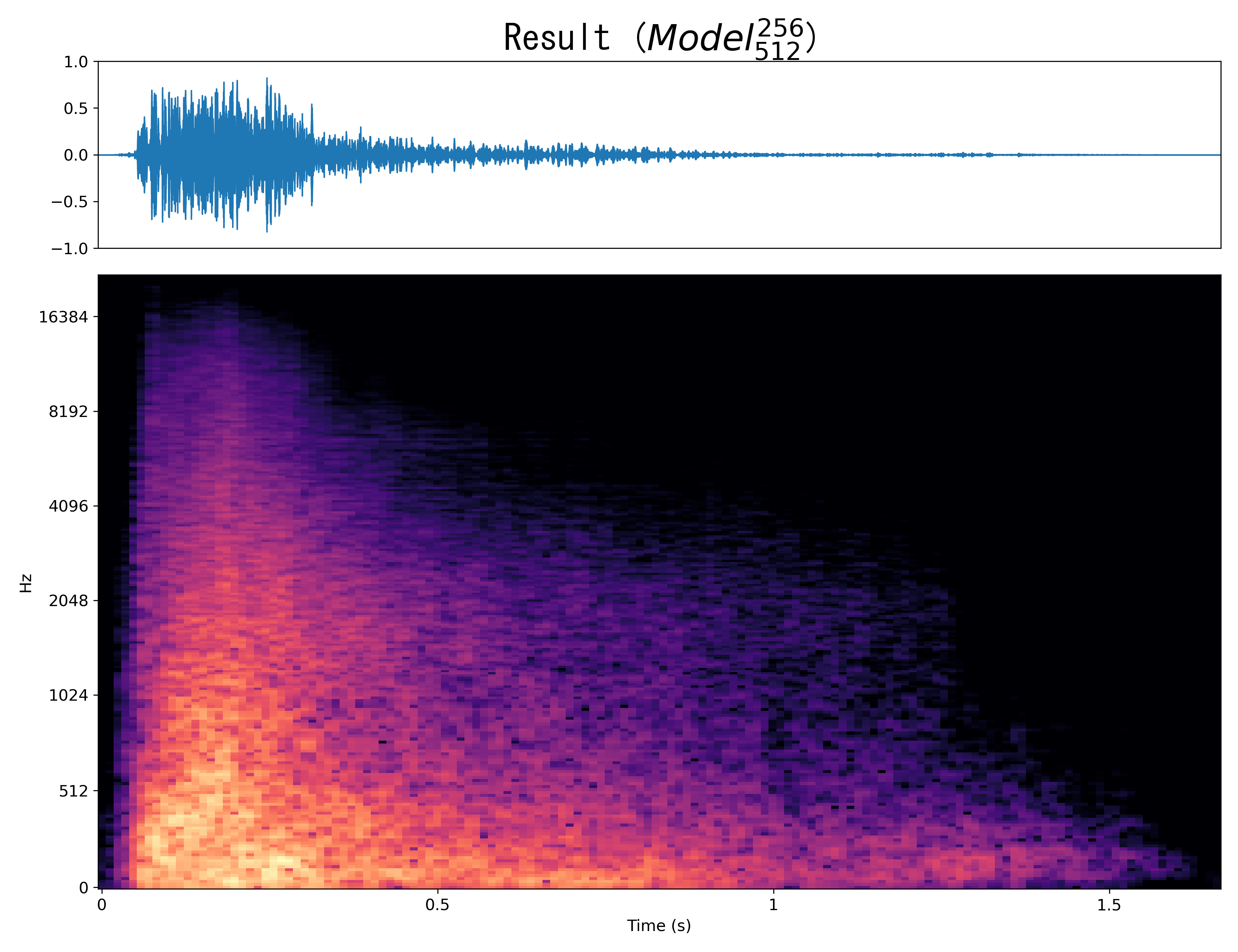
Result2
Mel-spec |
 |
 |
 |
 |
|---|---|---|---|---|
Result3
Mel-spec |
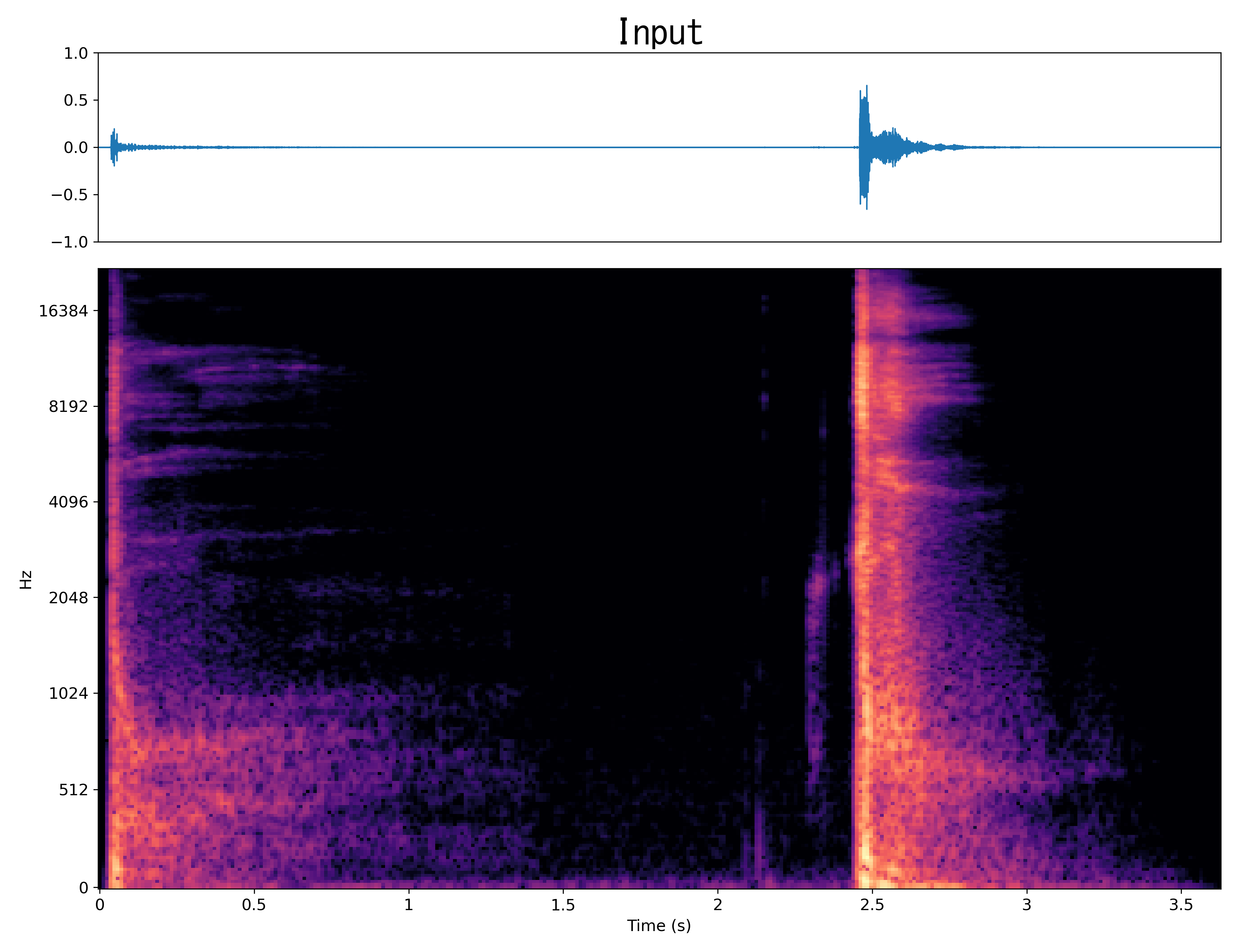 |
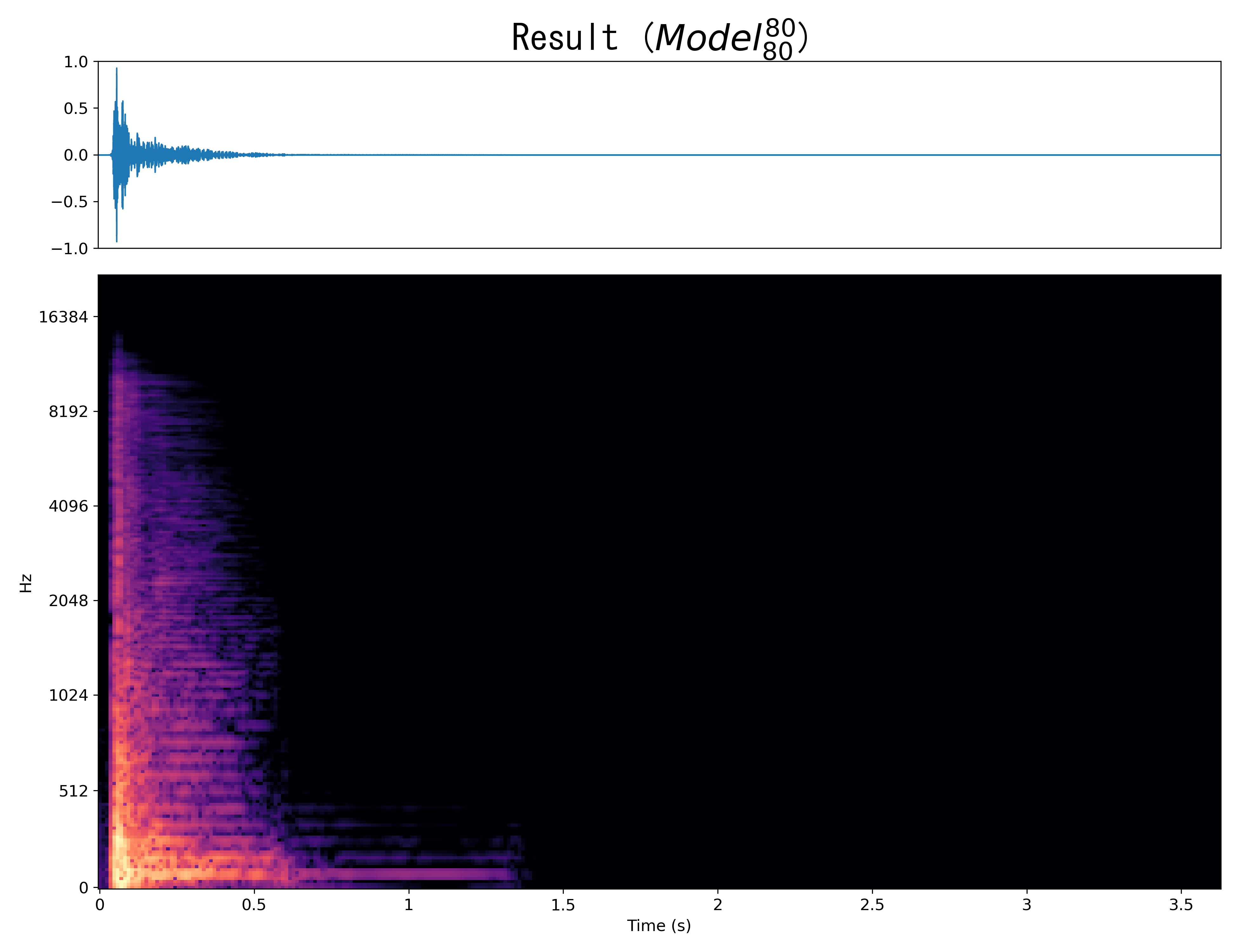 |
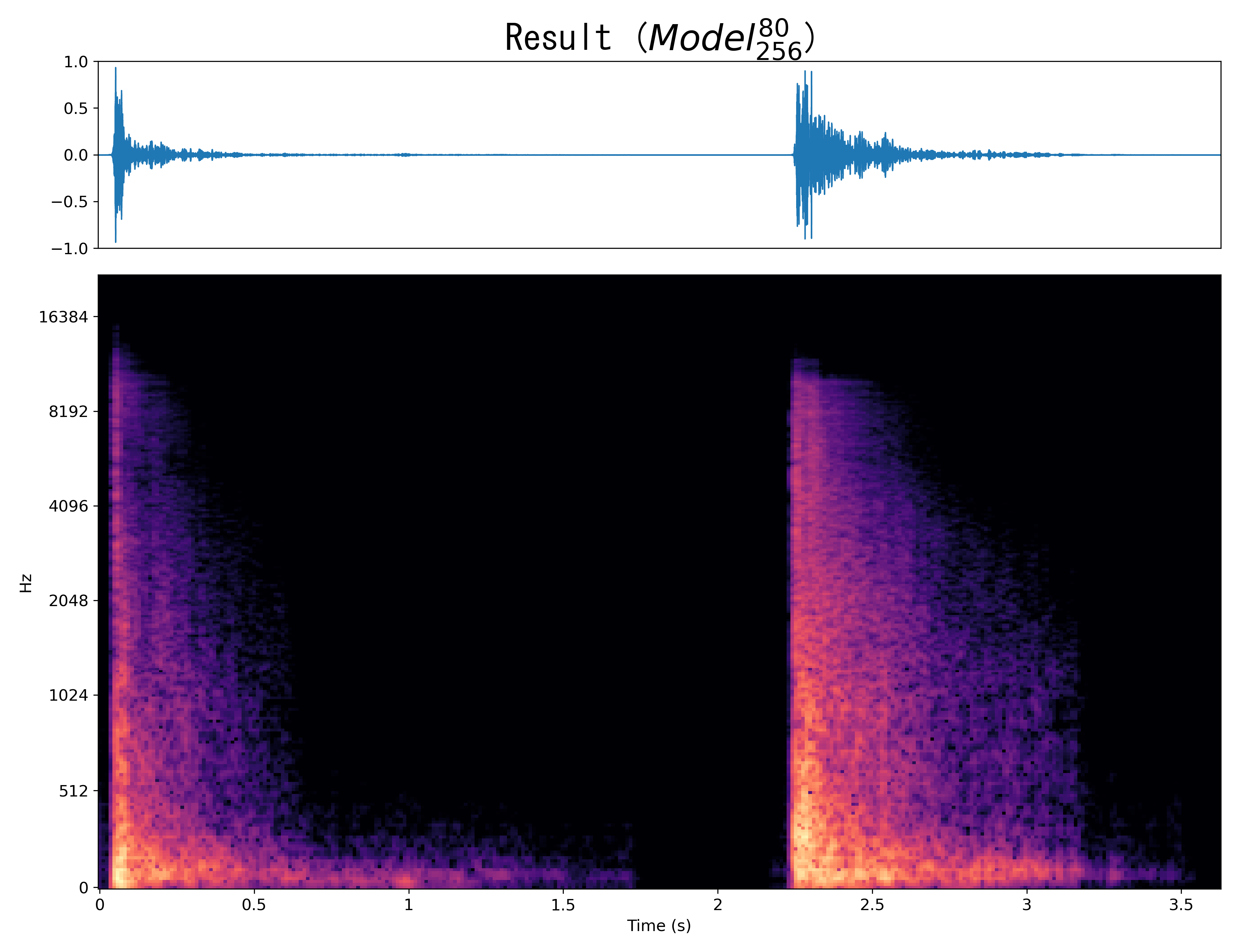 |
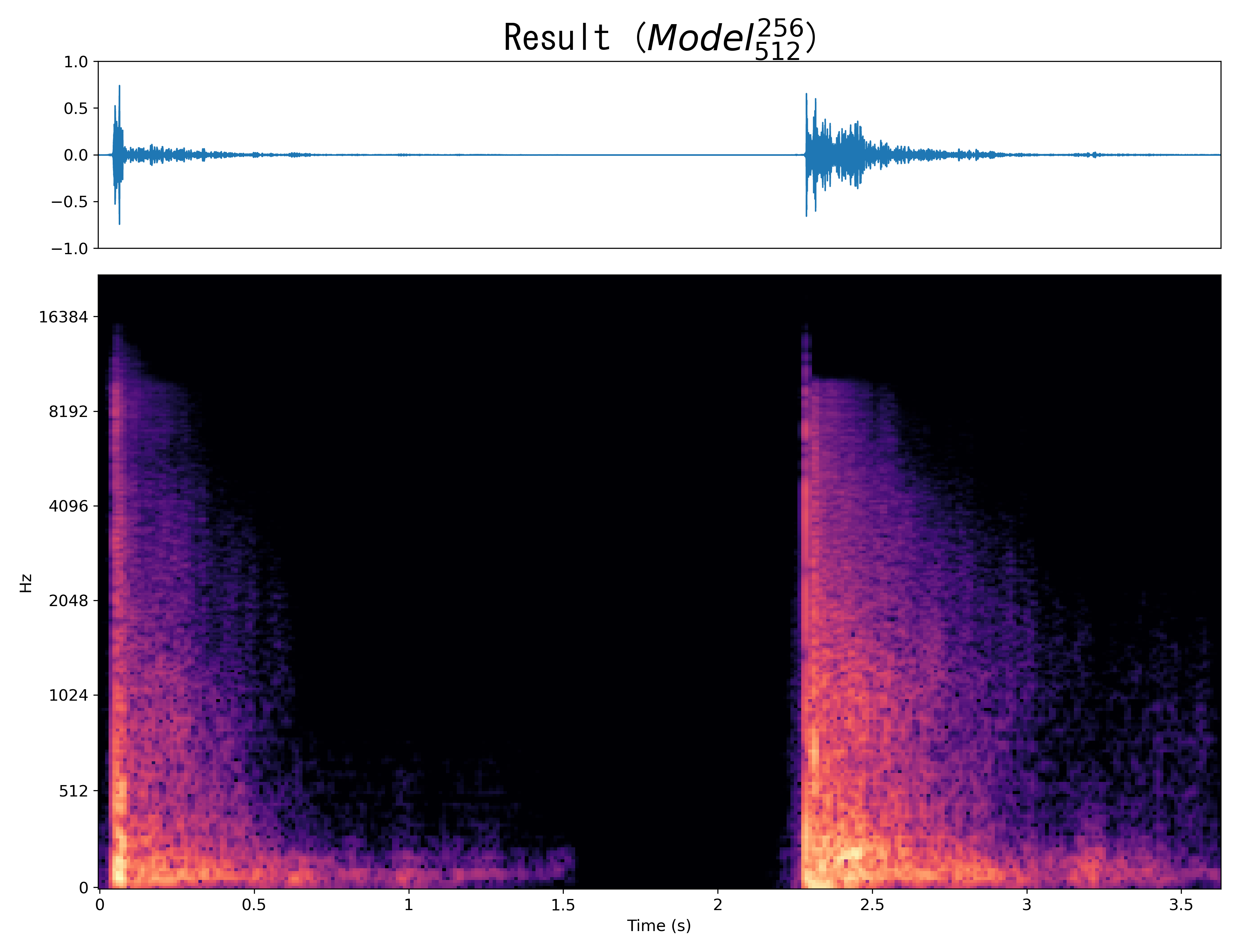 |
|---|---|---|---|---|
Result4
Mel-spec |
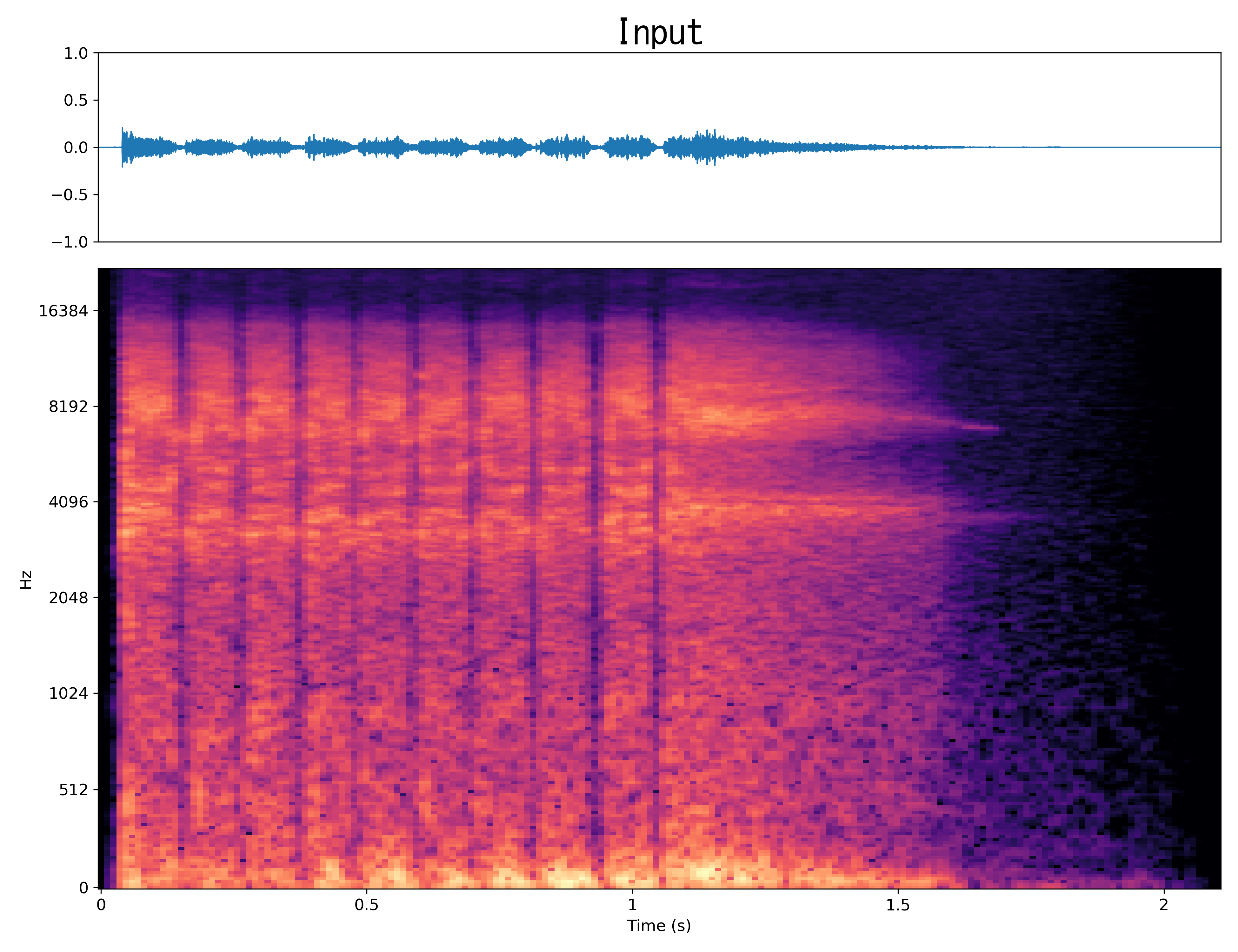 |
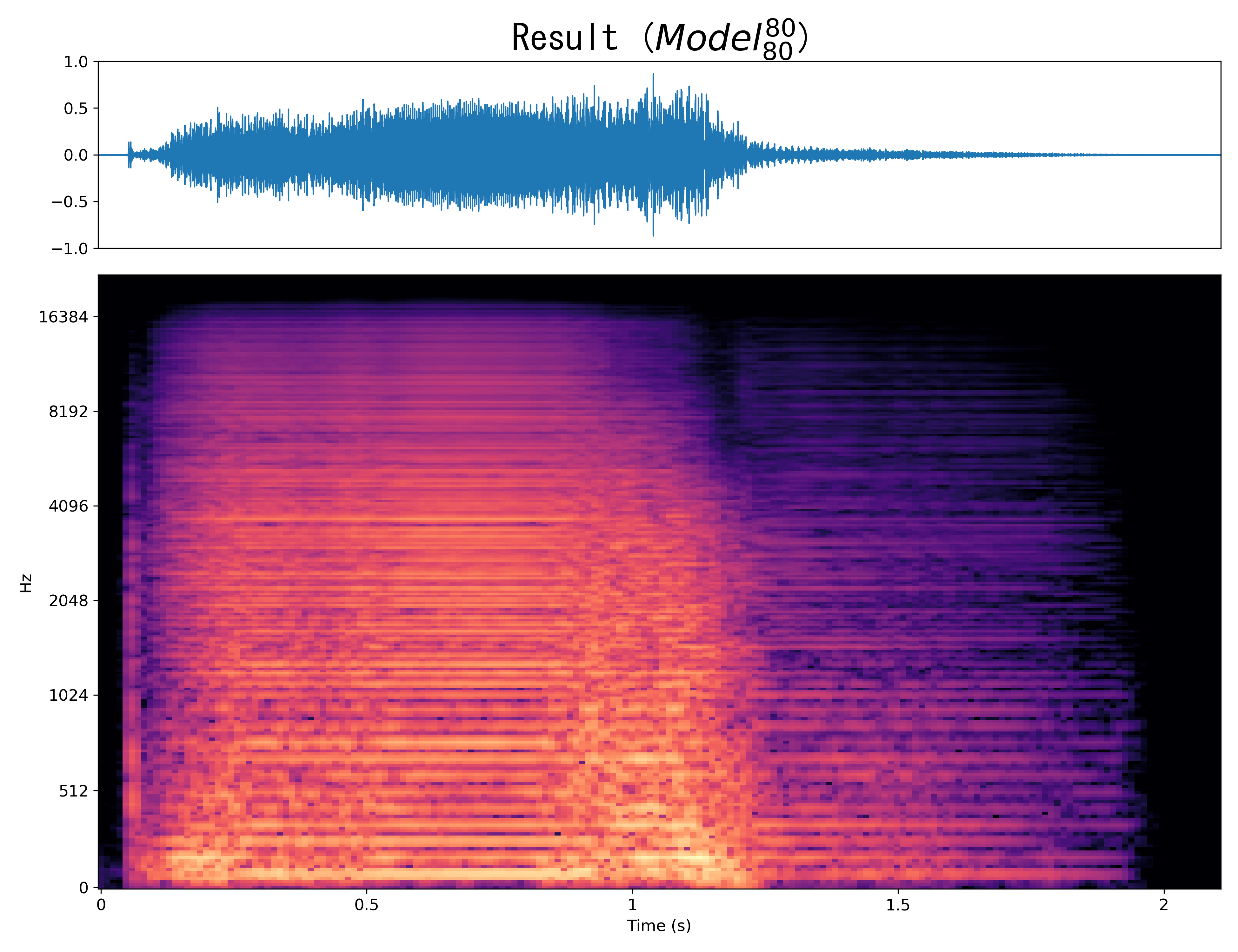 |
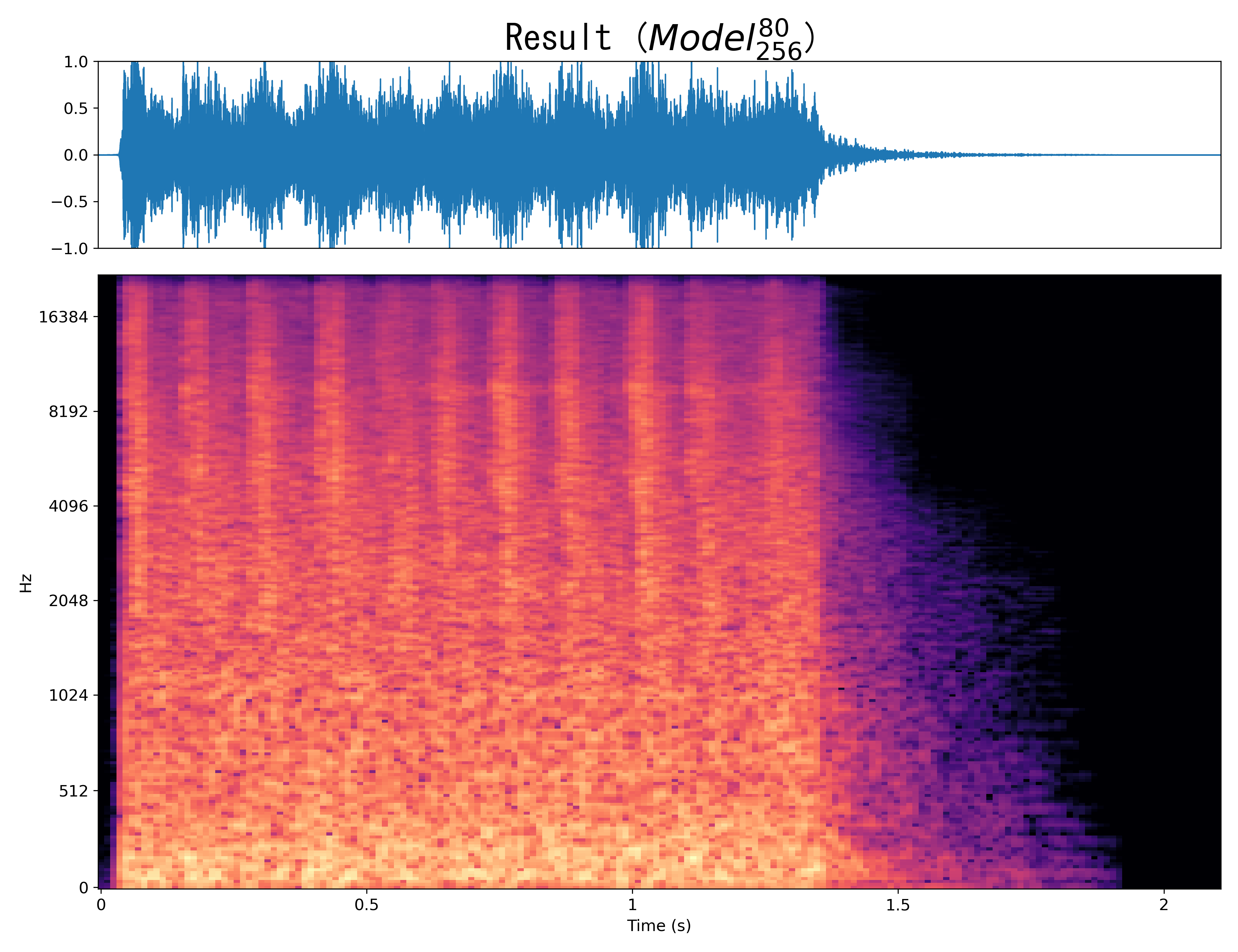 |
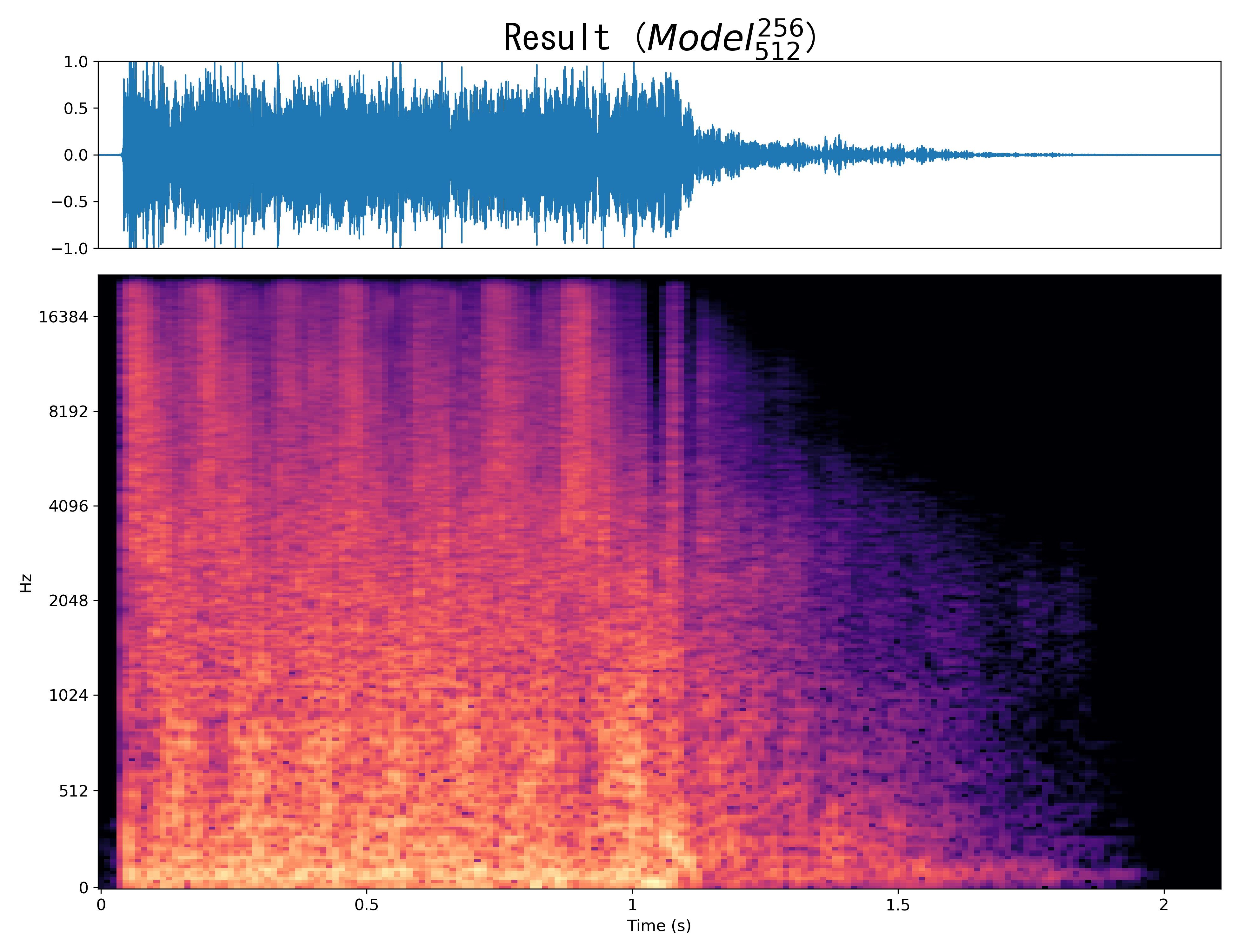 |
|---|---|---|---|---|
Result5
Mel-spec |
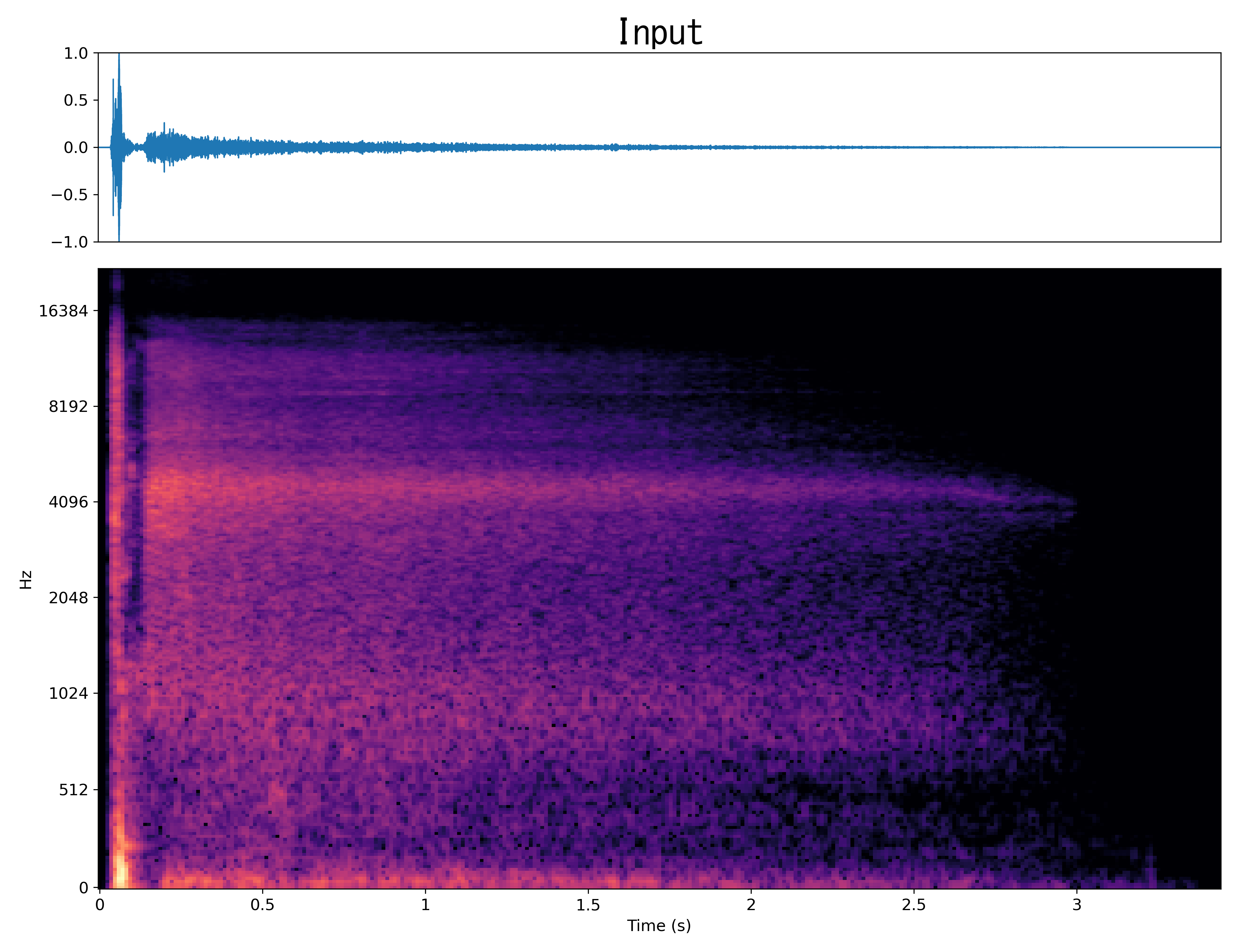 |
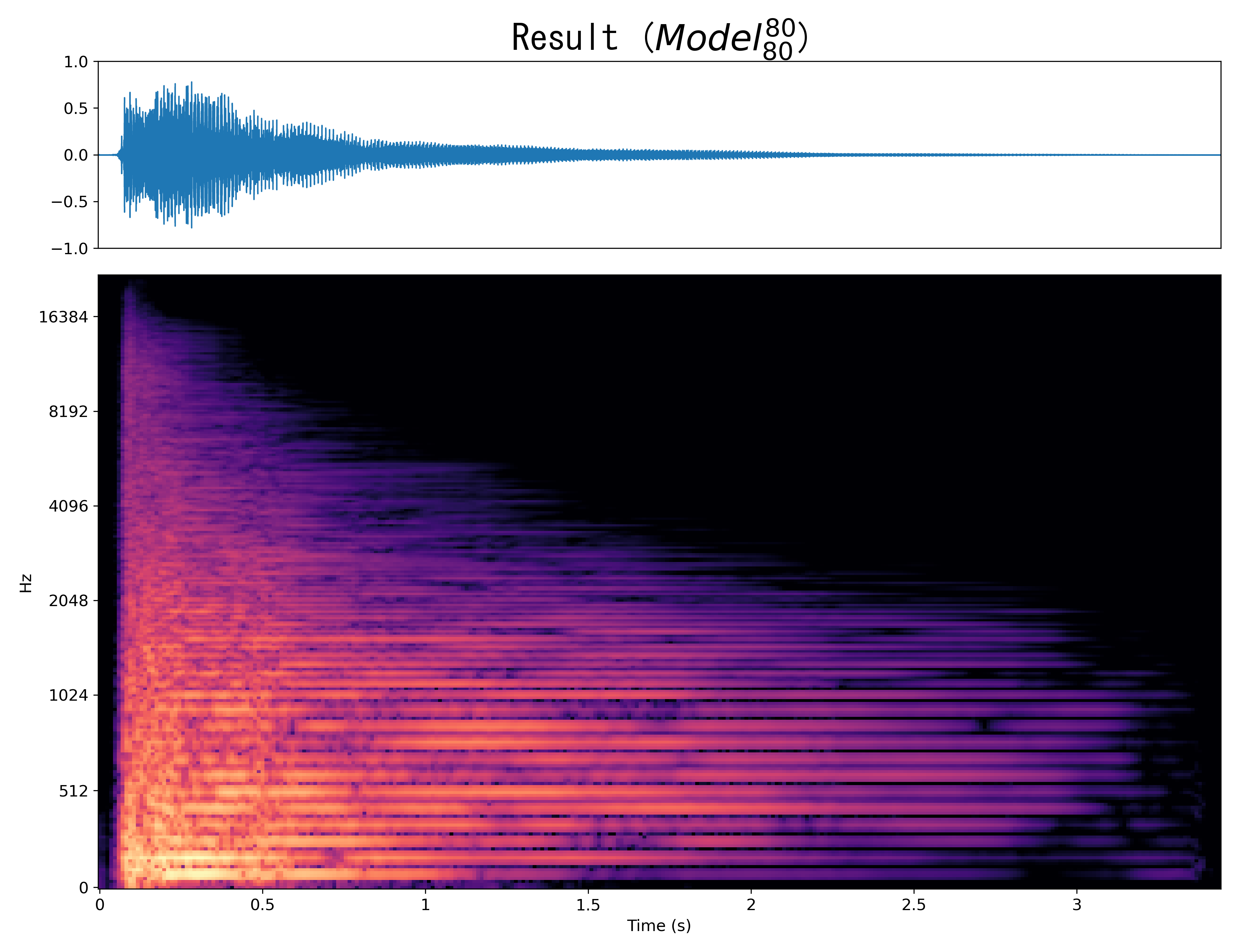 |
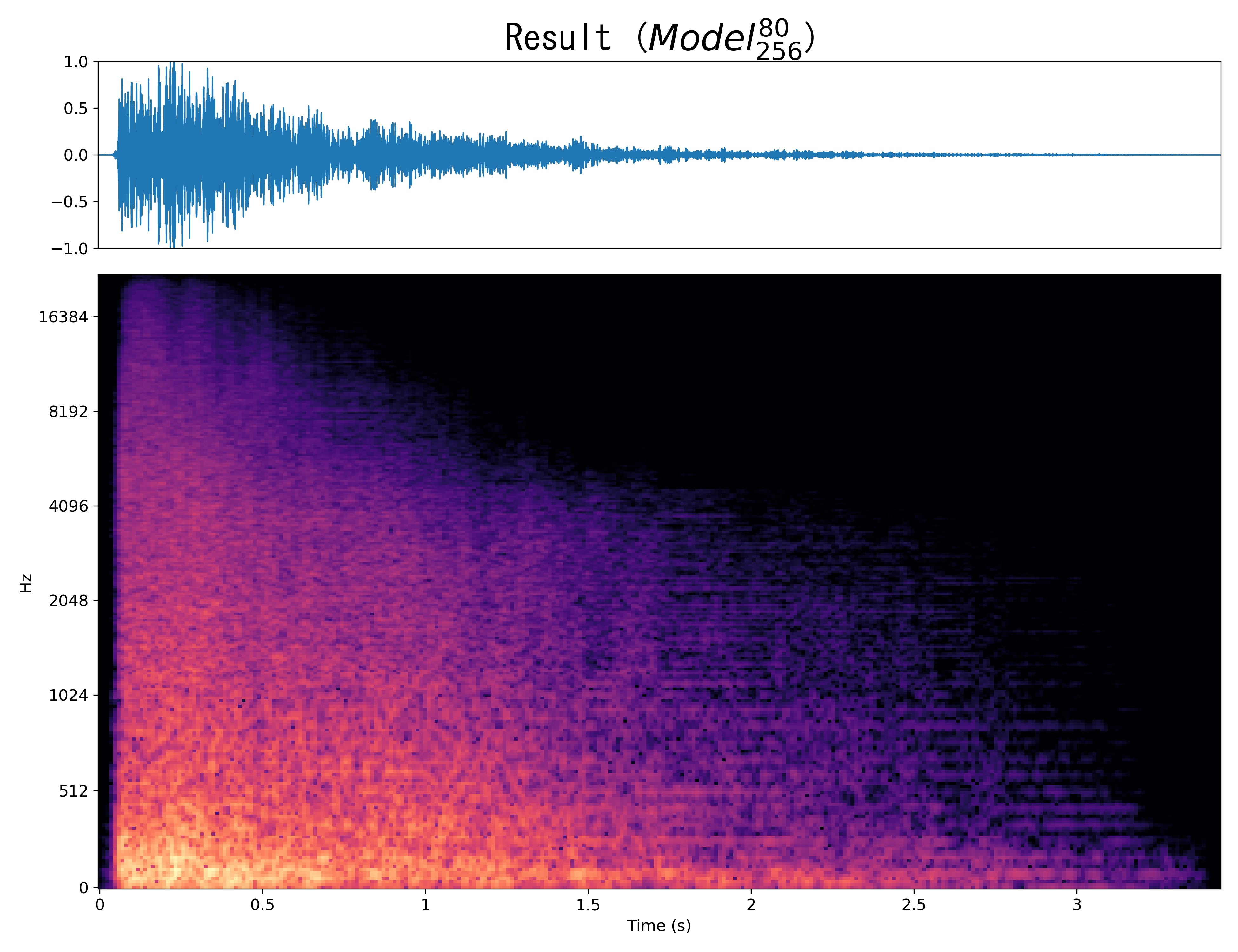 |
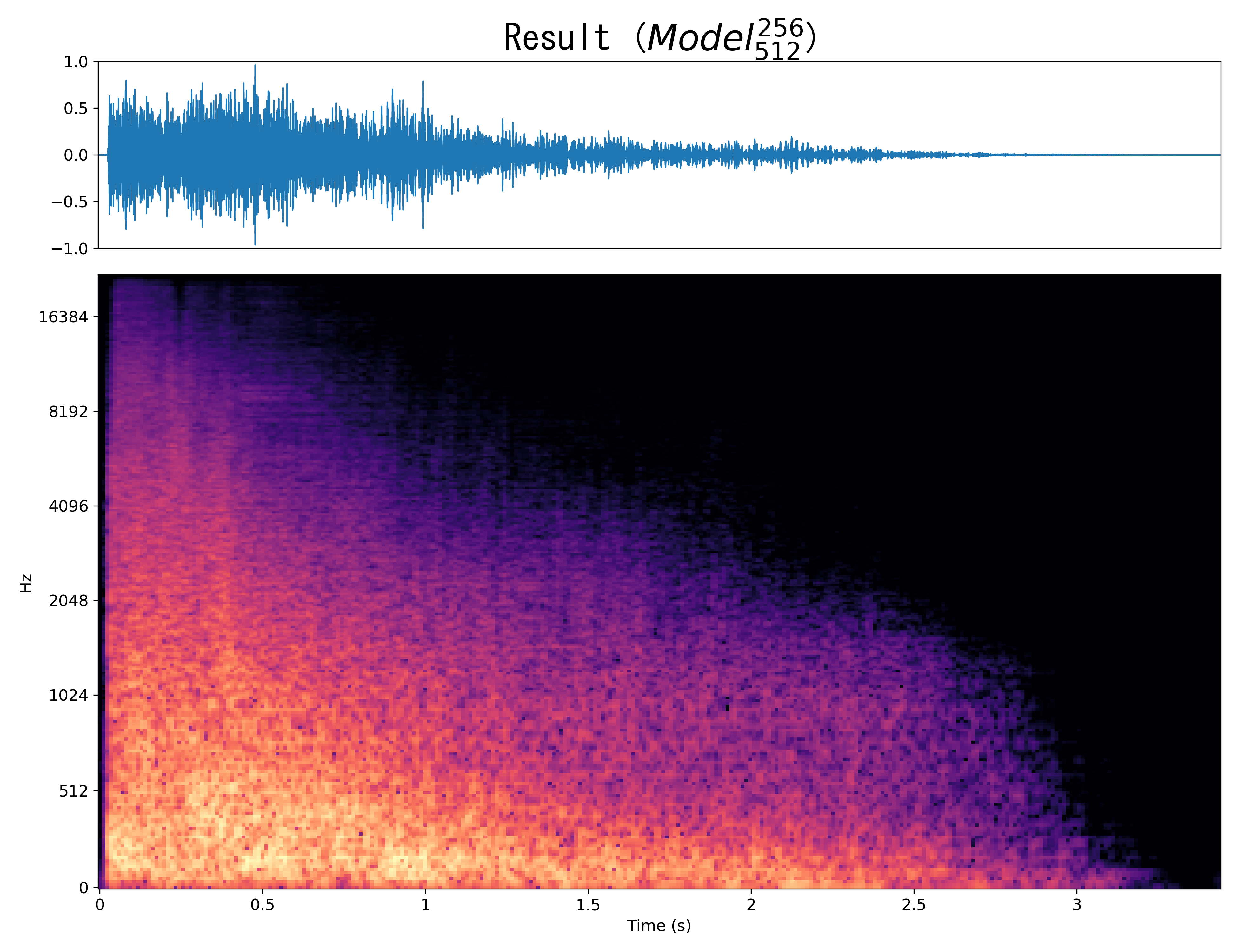 |
|---|---|---|---|---|
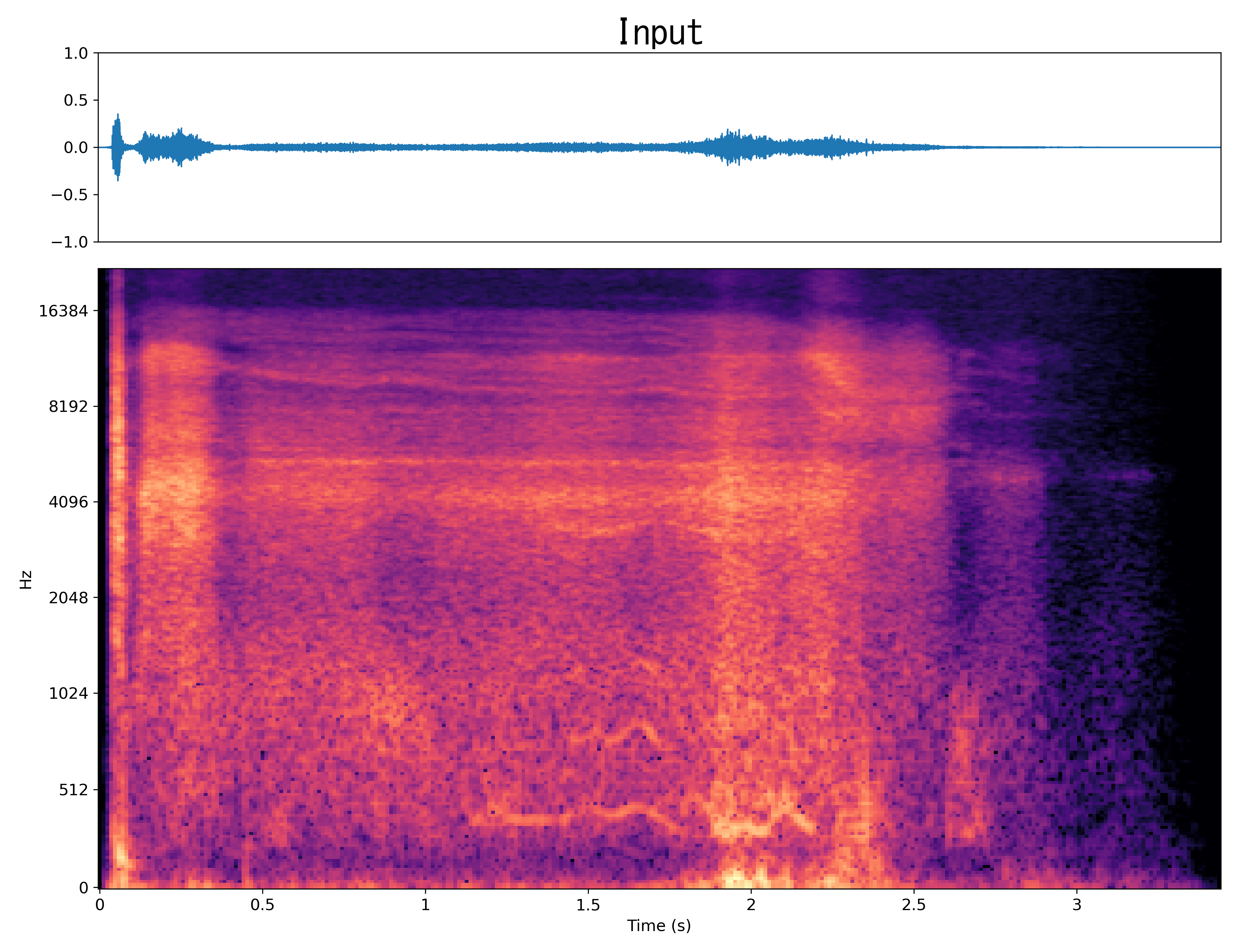
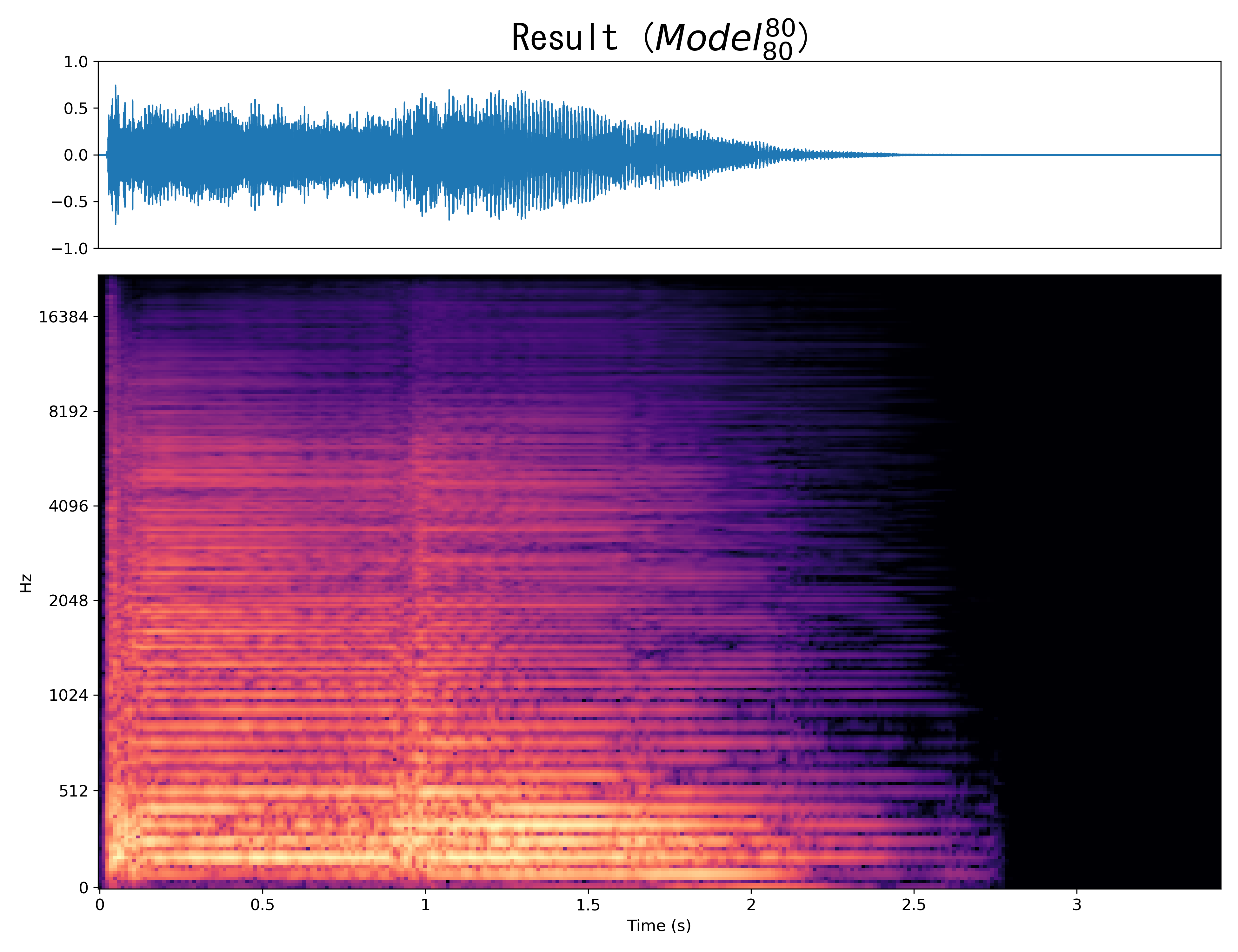
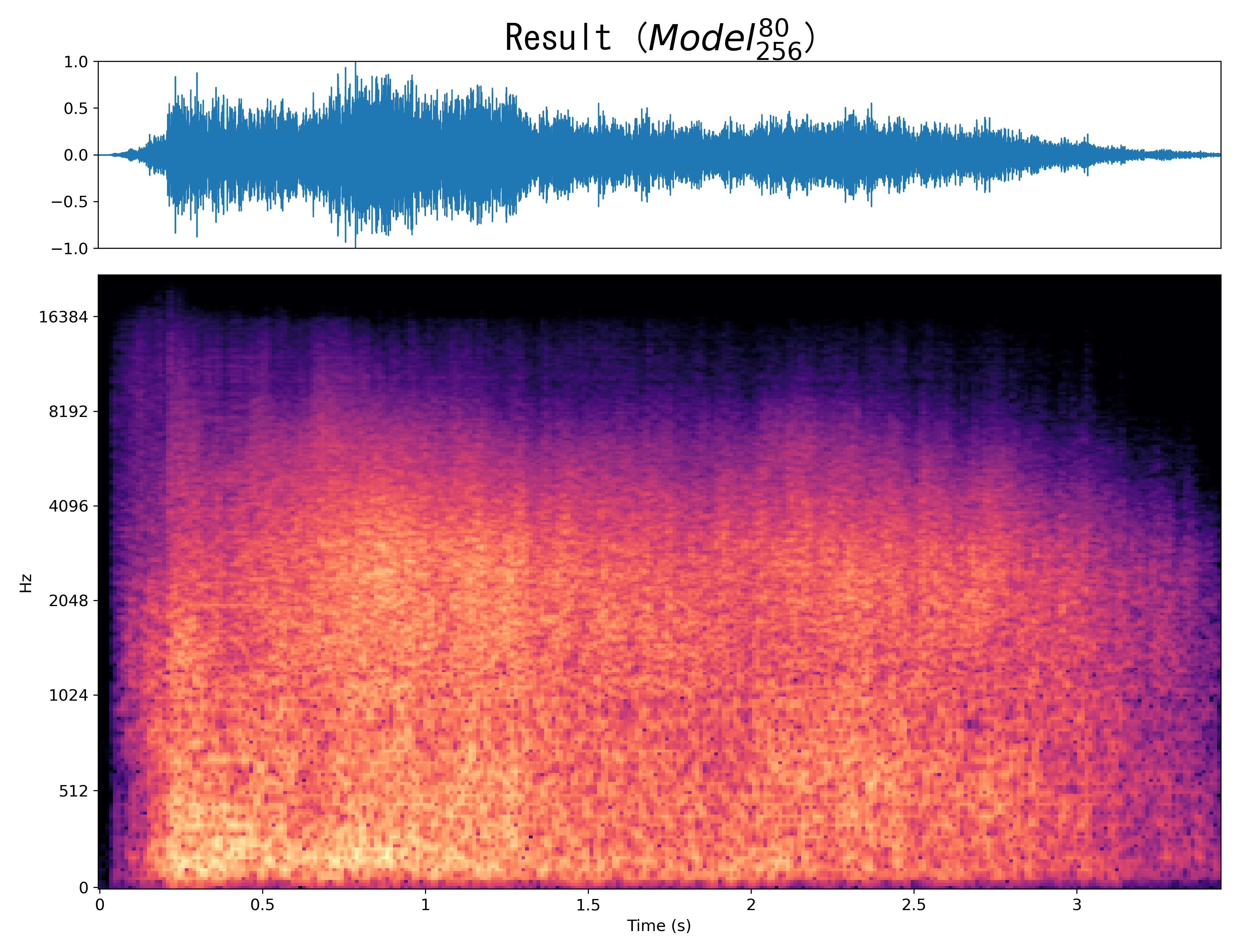
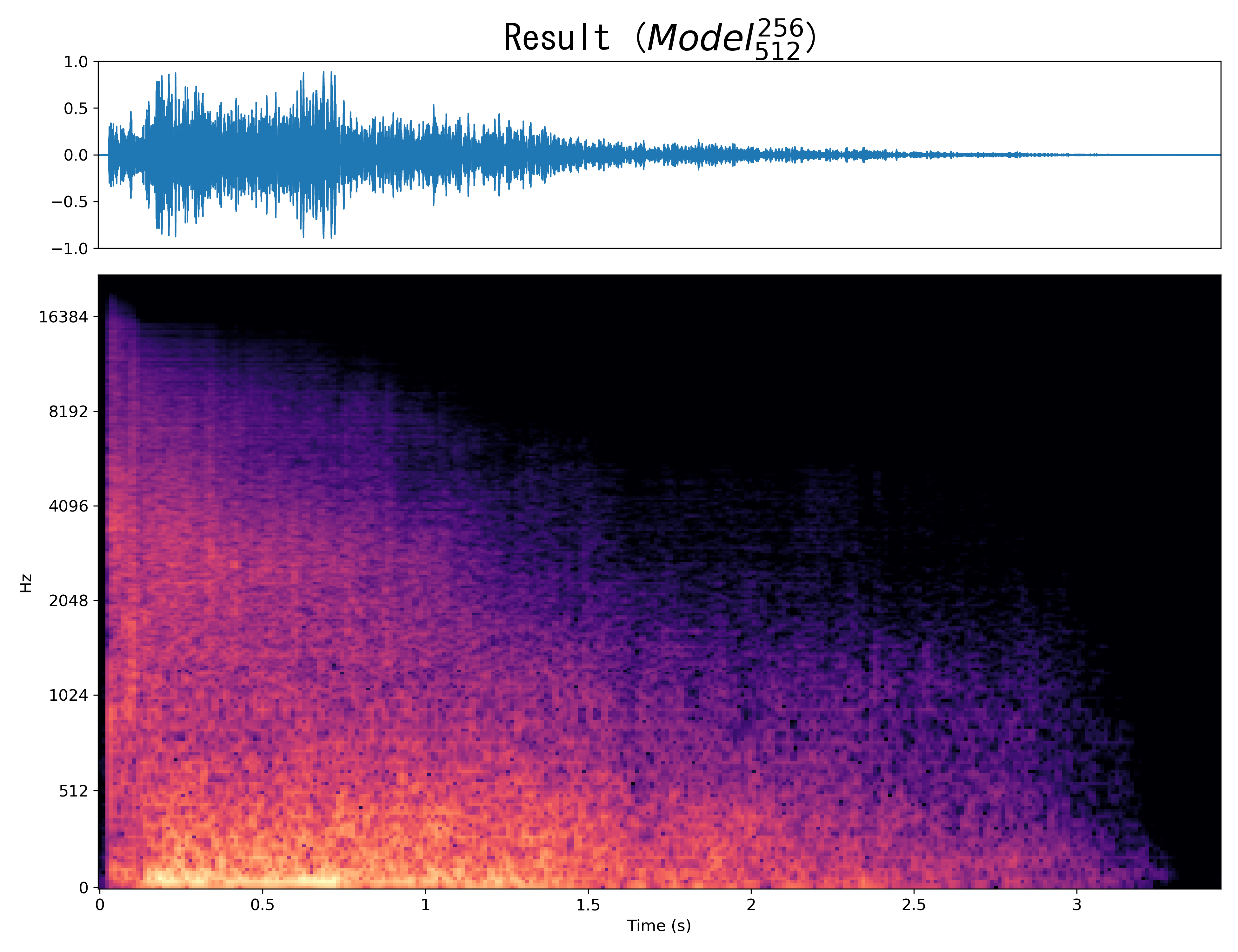
Result6
Mel-spec |
 |
 |
 |
 |
|---|---|---|---|---|
Result7
Mel-spec |
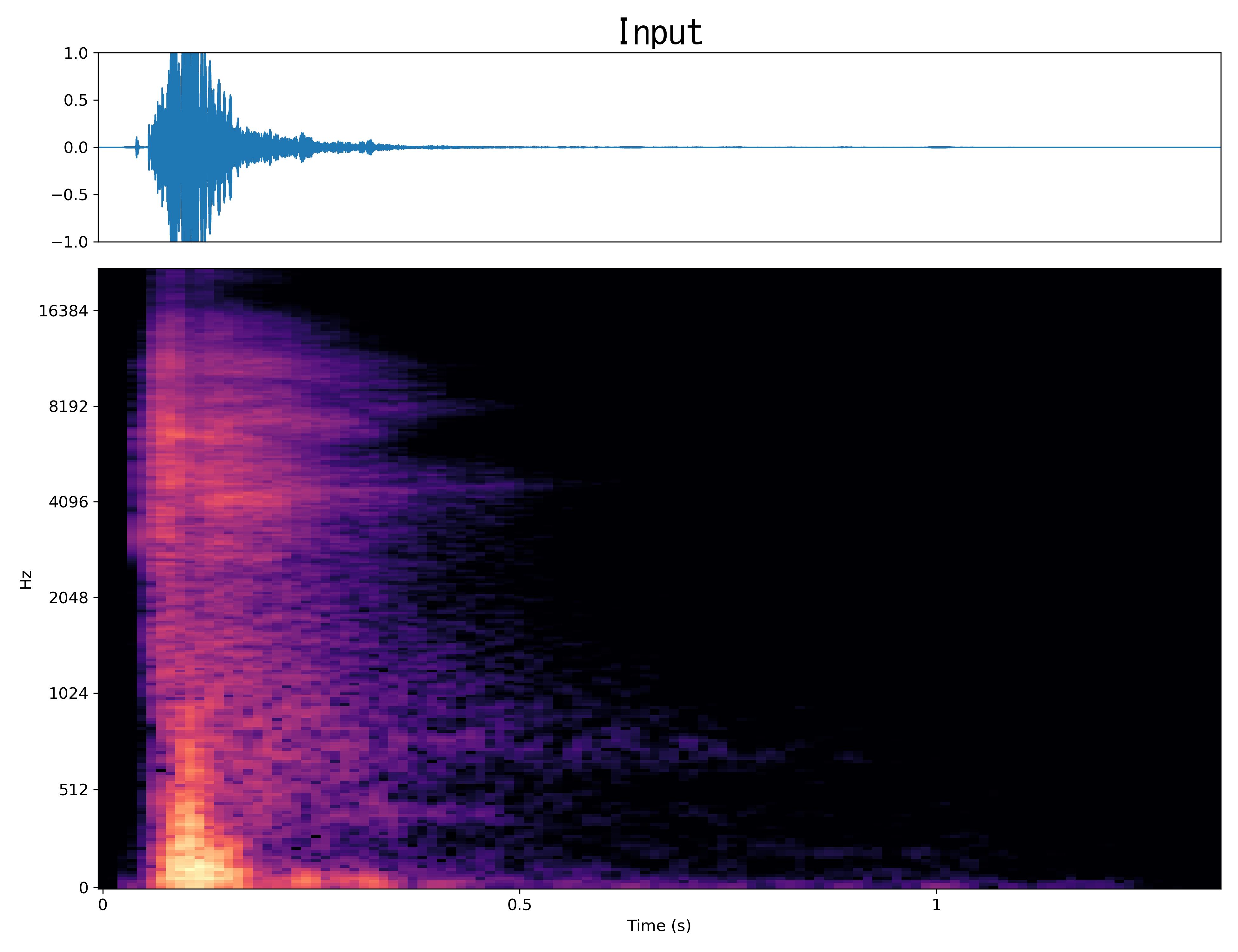 |
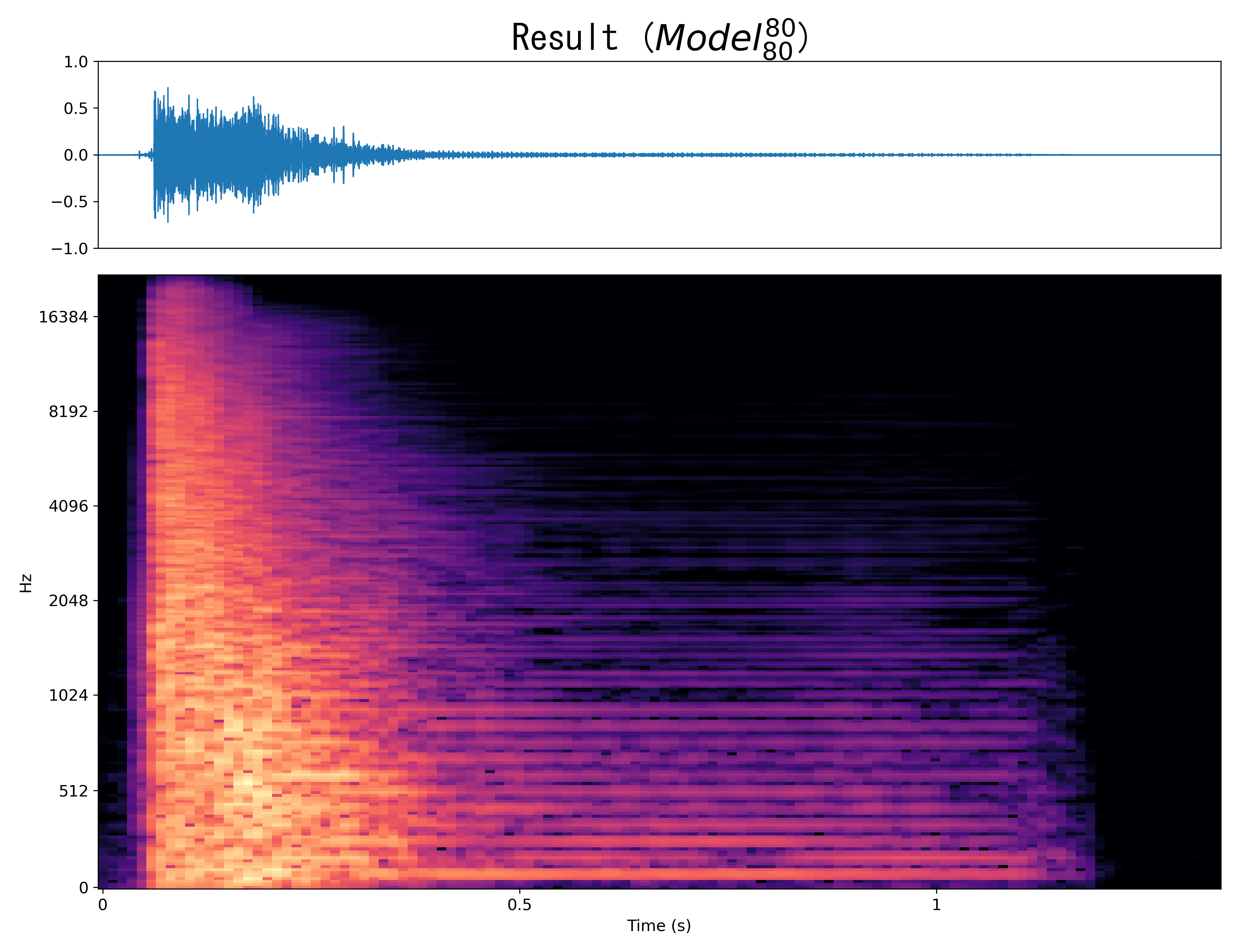 |
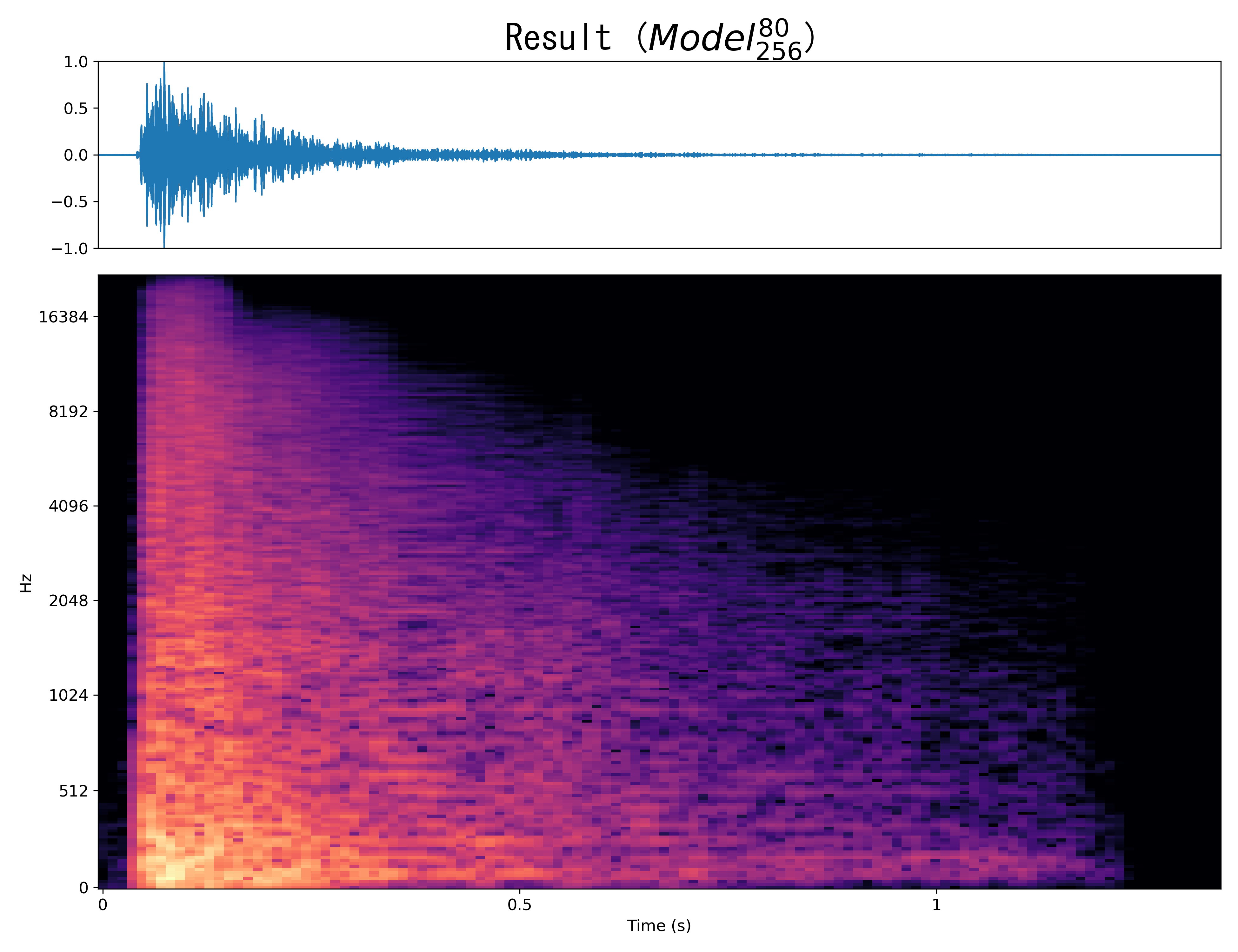 |
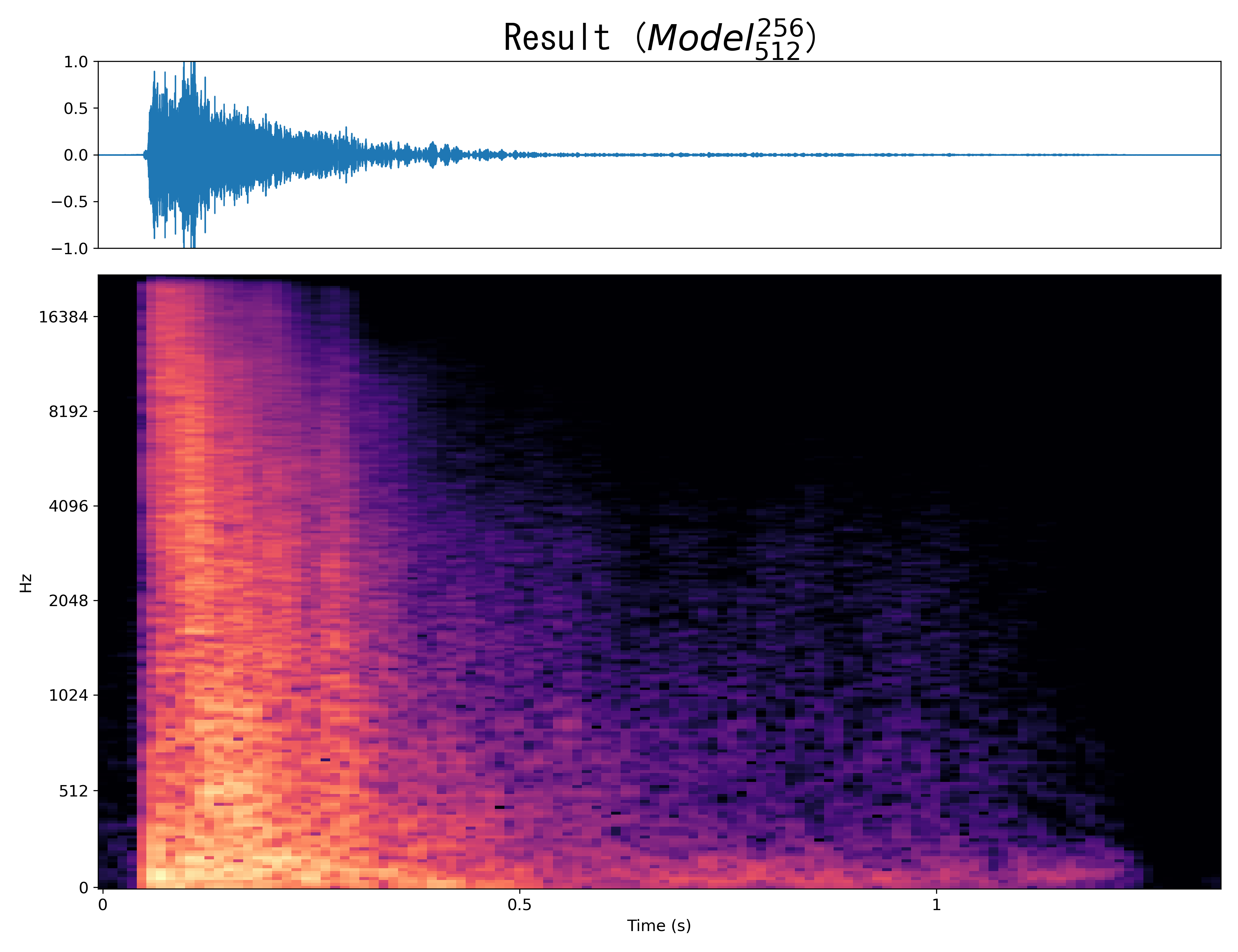 |
|---|---|---|---|---|
Result8
Mel-spec |
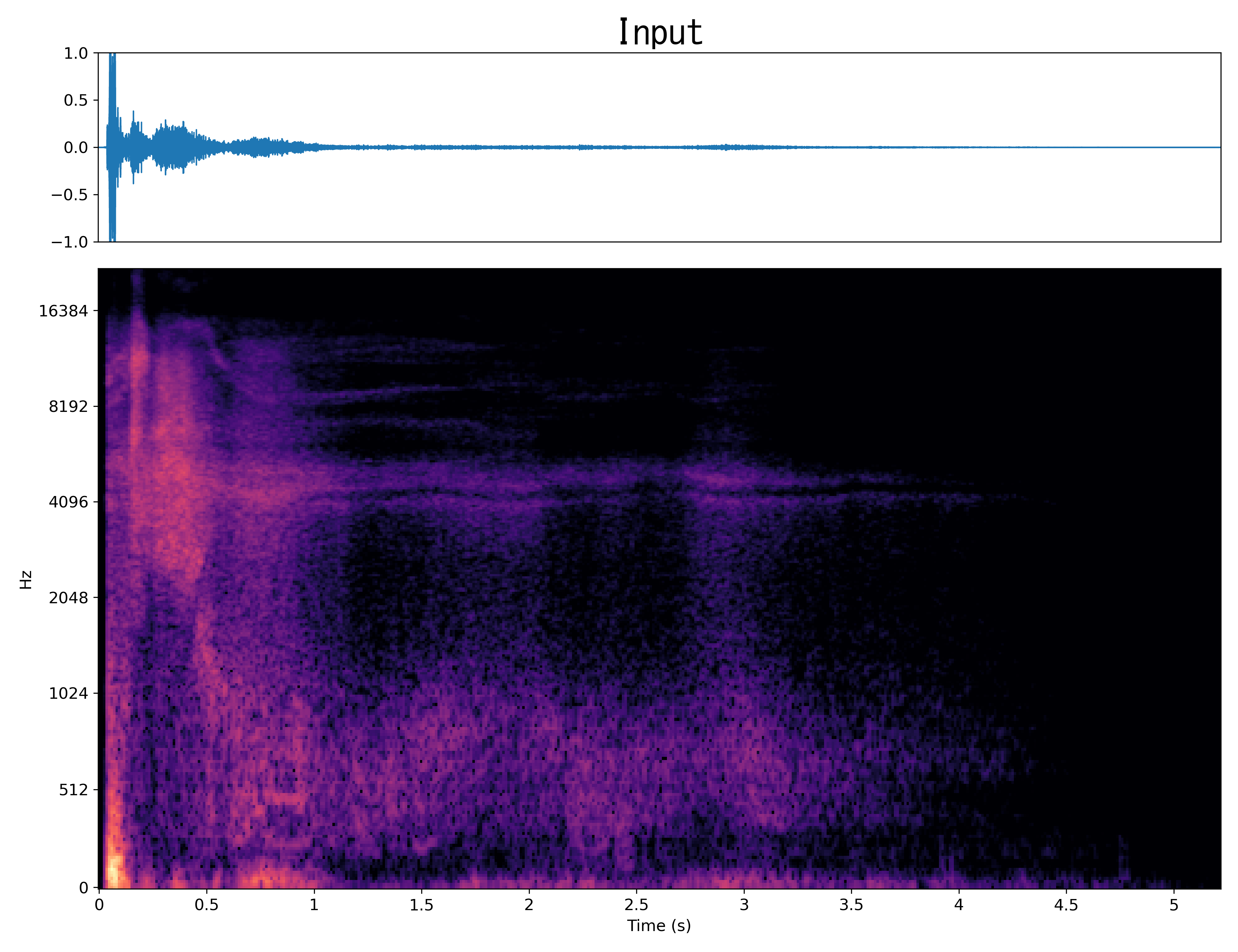 |
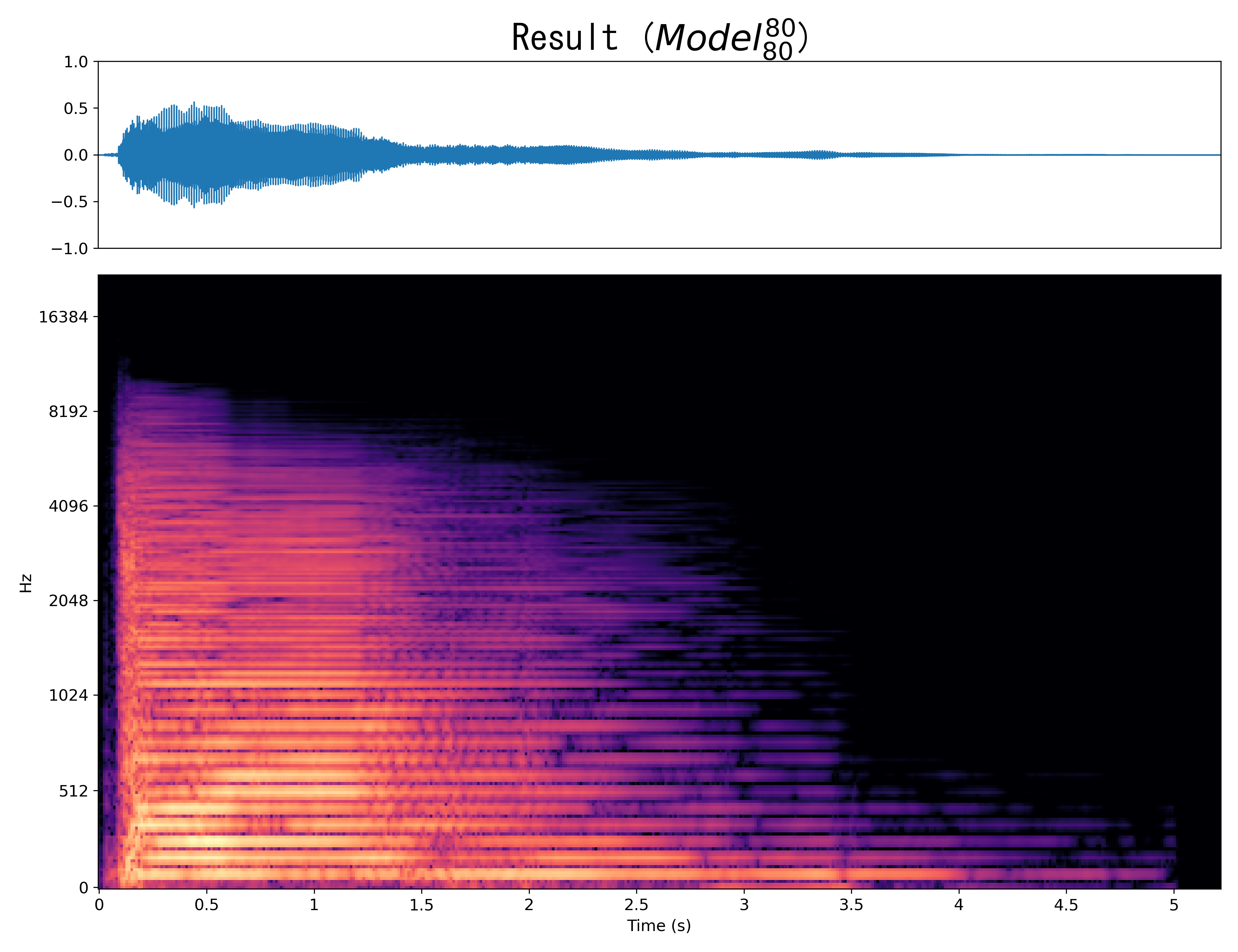 |
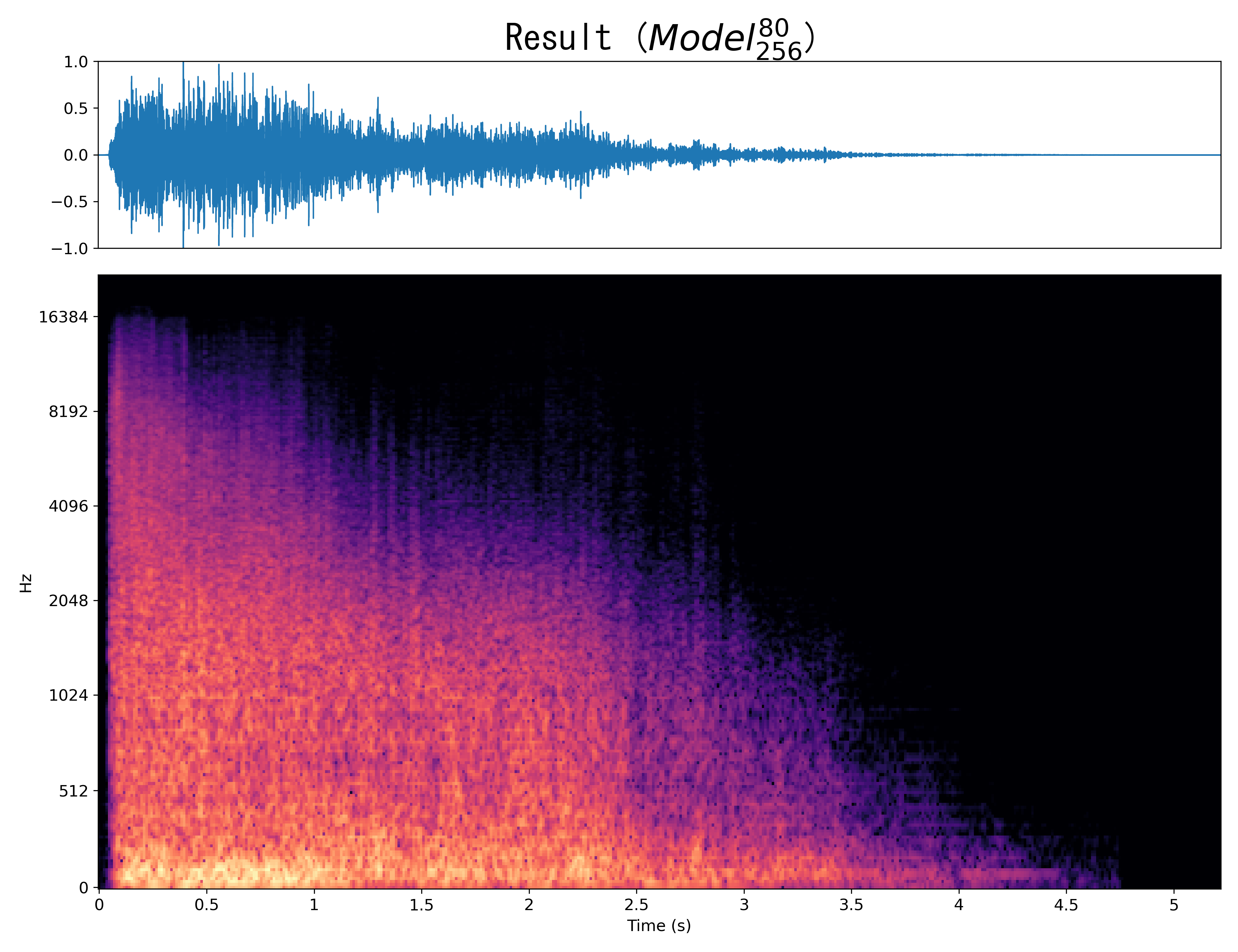 |
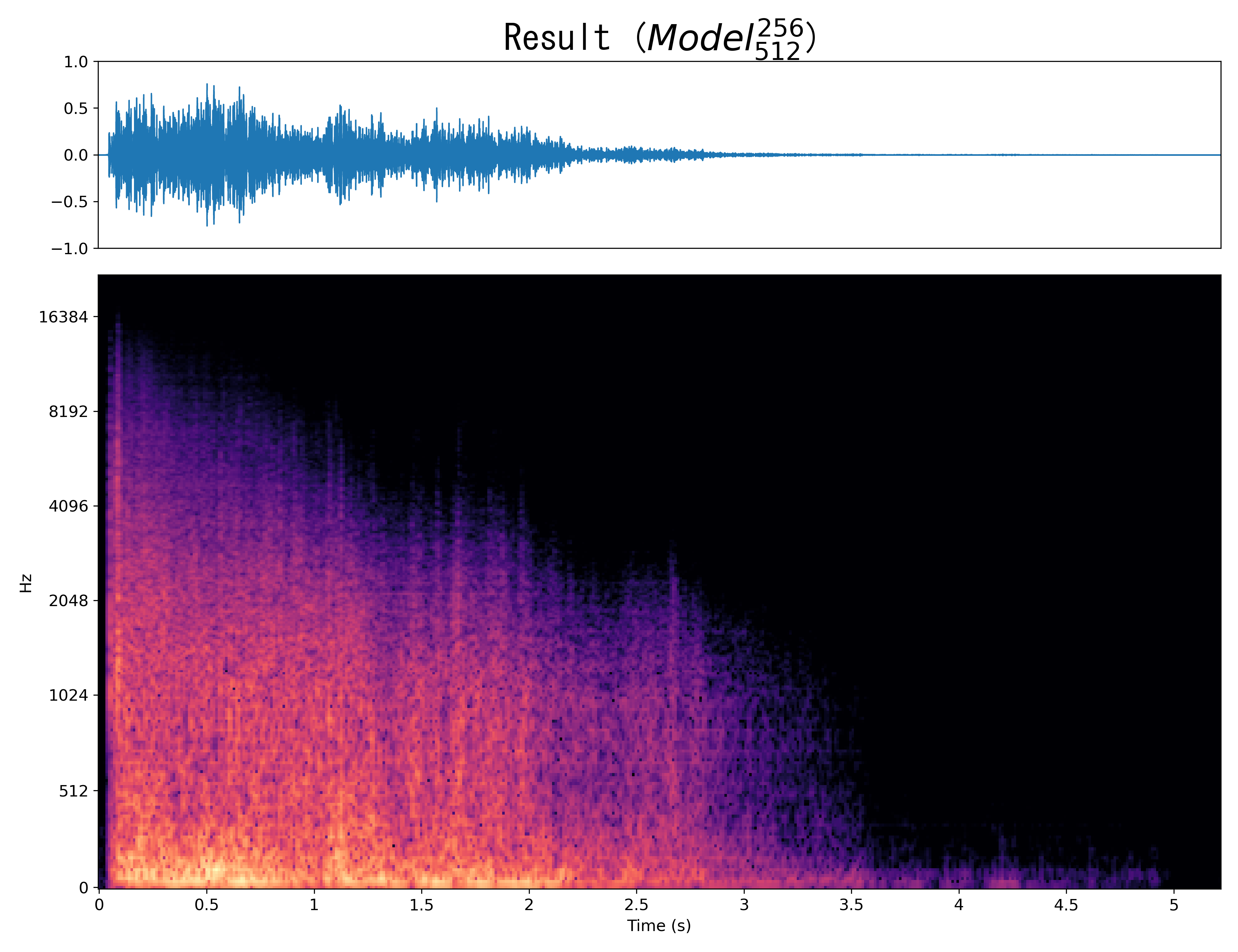 |
|---|---|---|---|---|
Result9
Mel-spec |
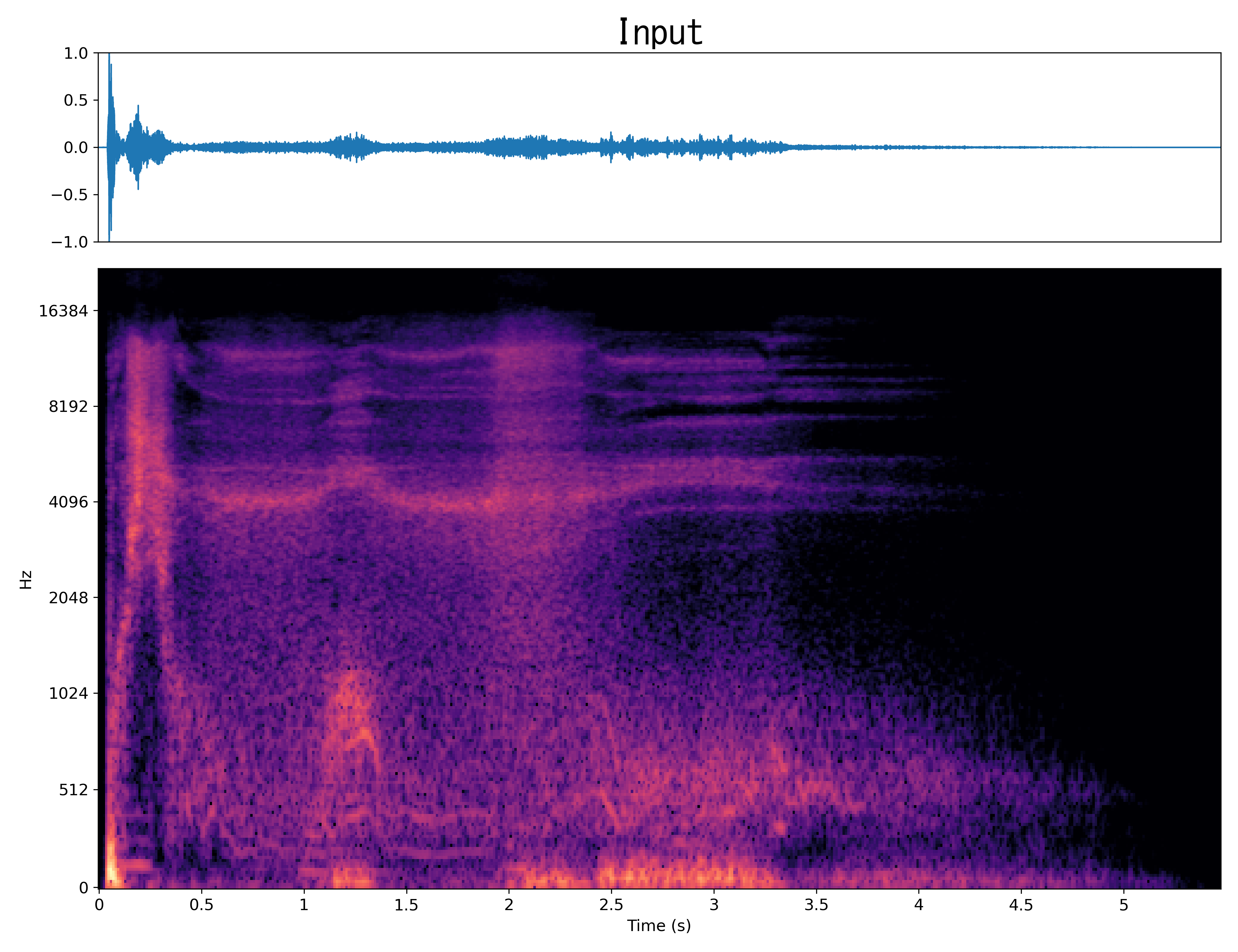 |
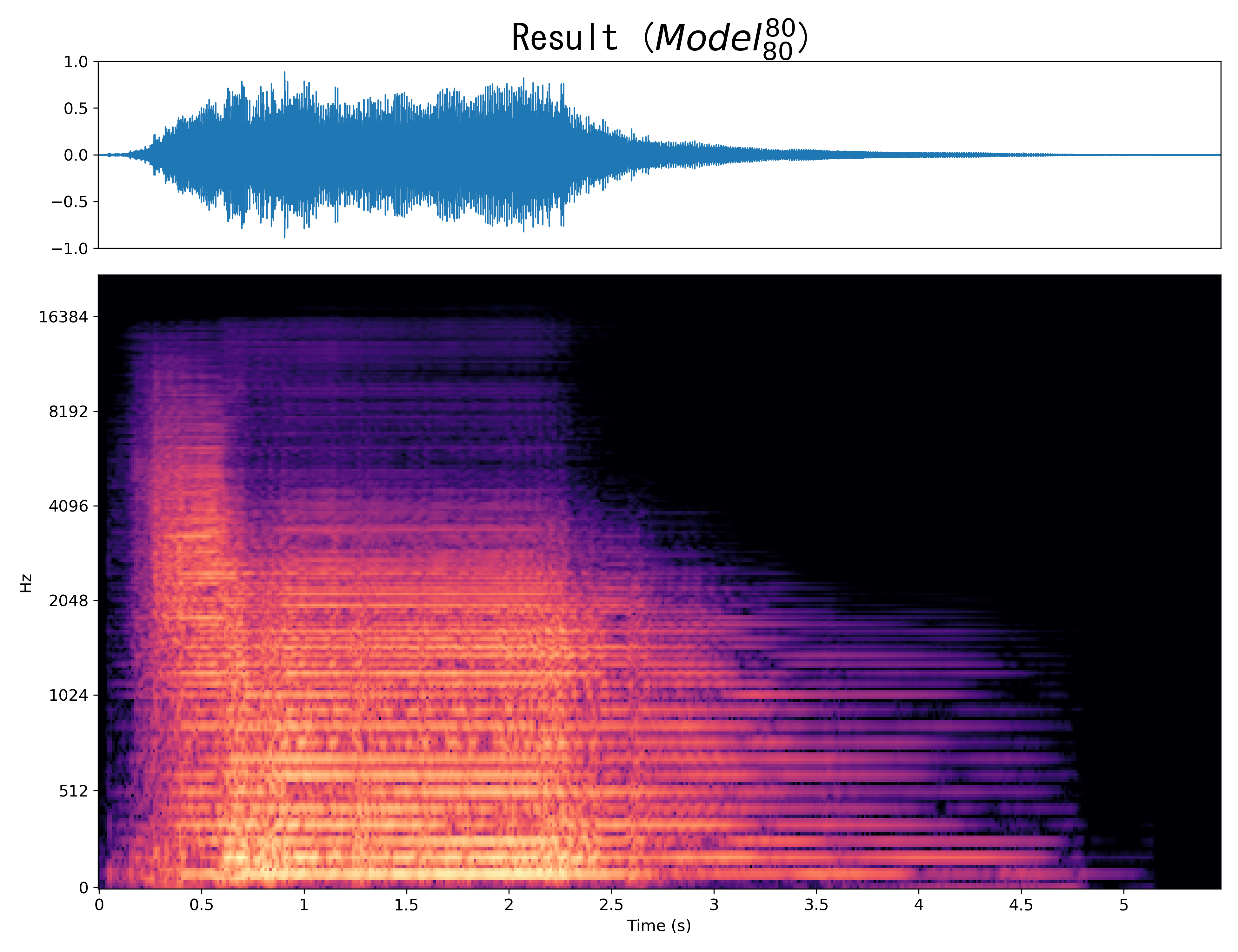 |
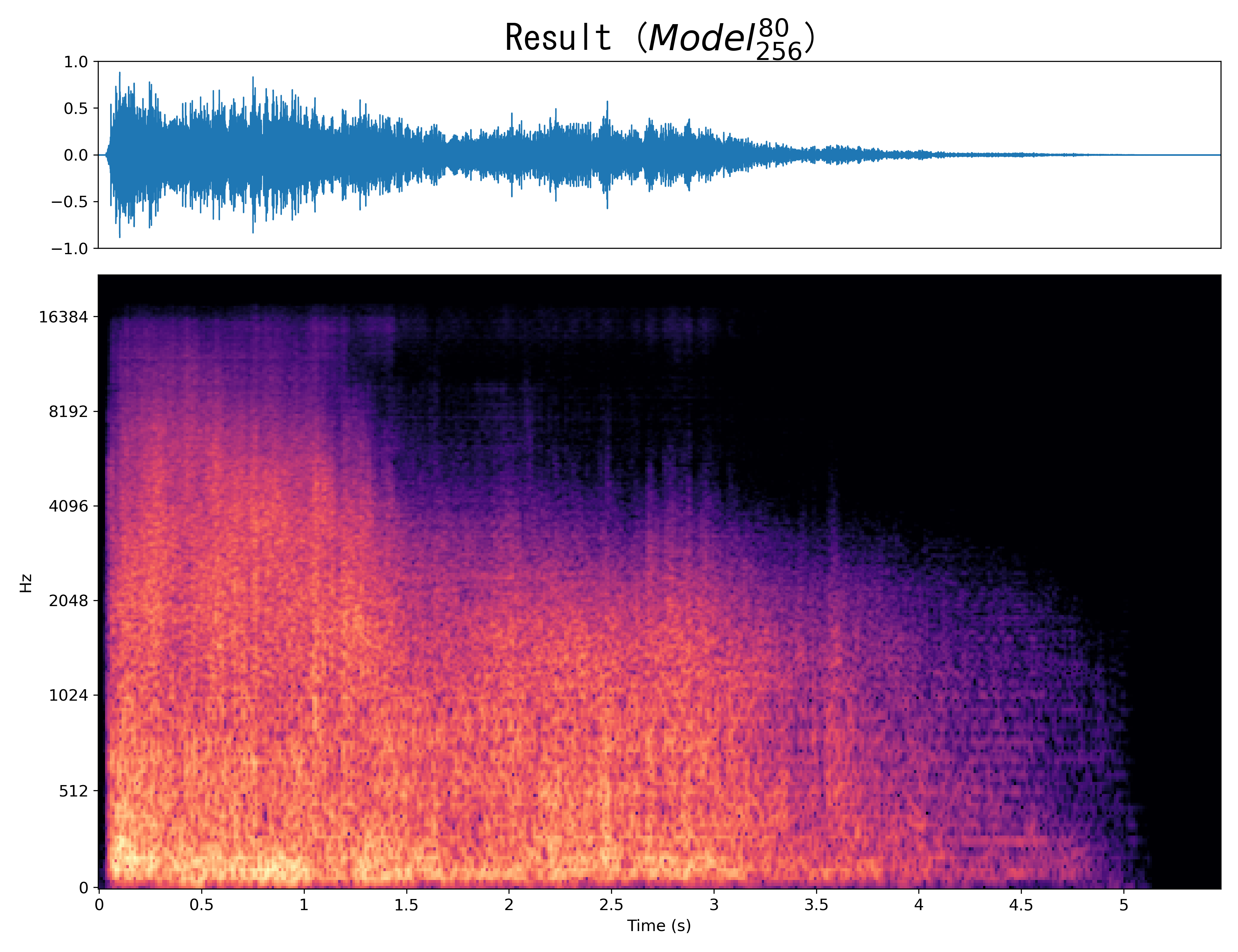 |
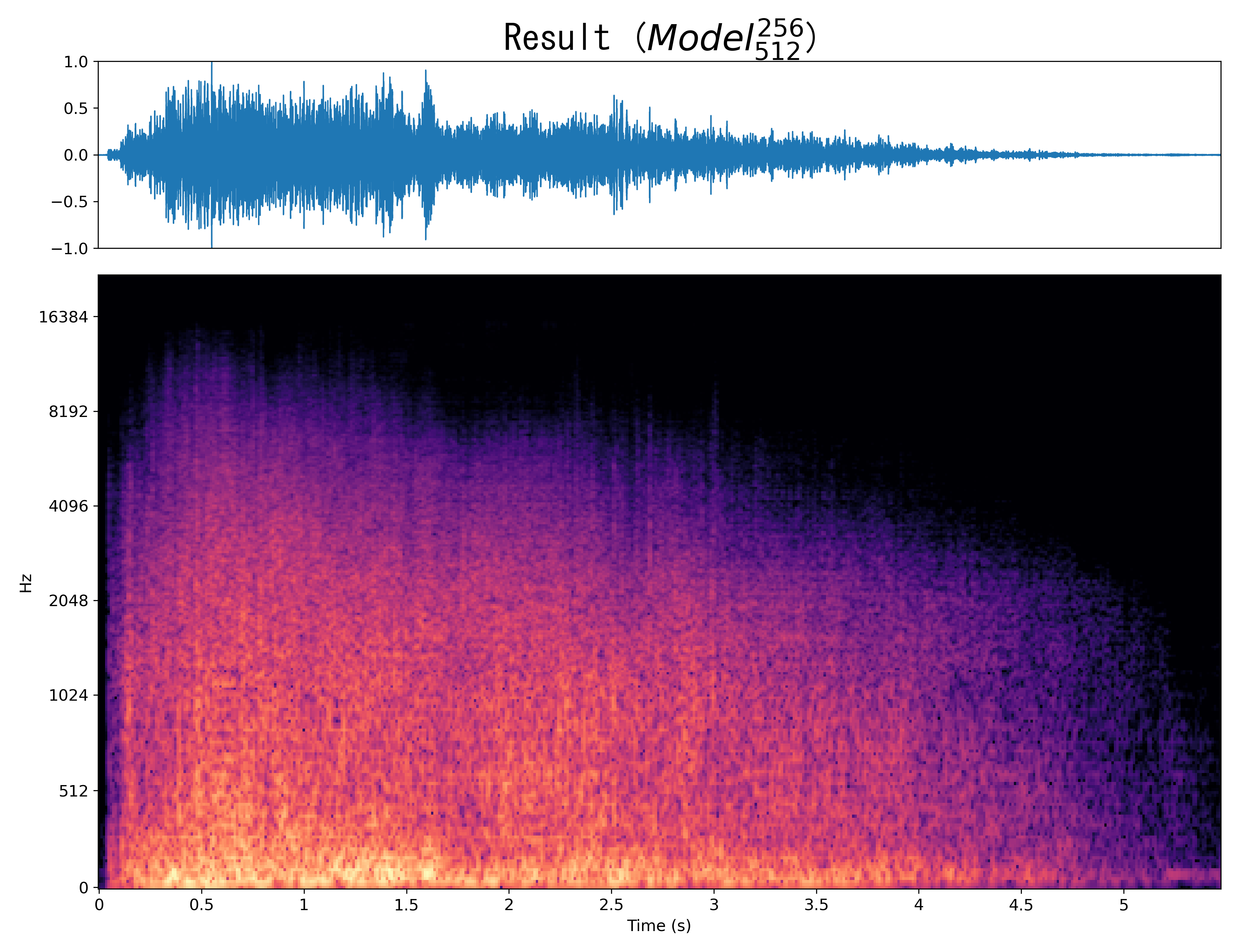 |
|---|---|---|---|---|
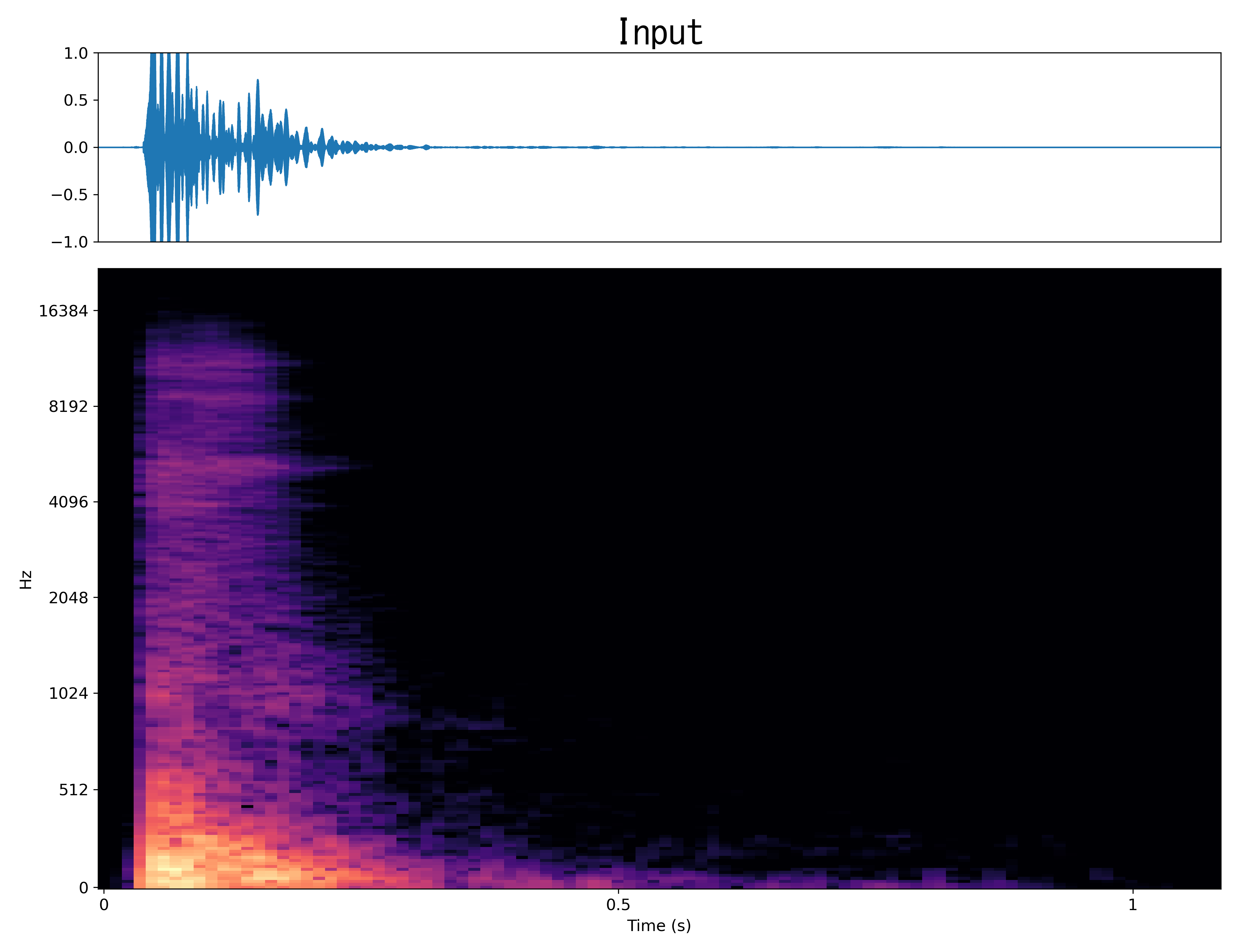
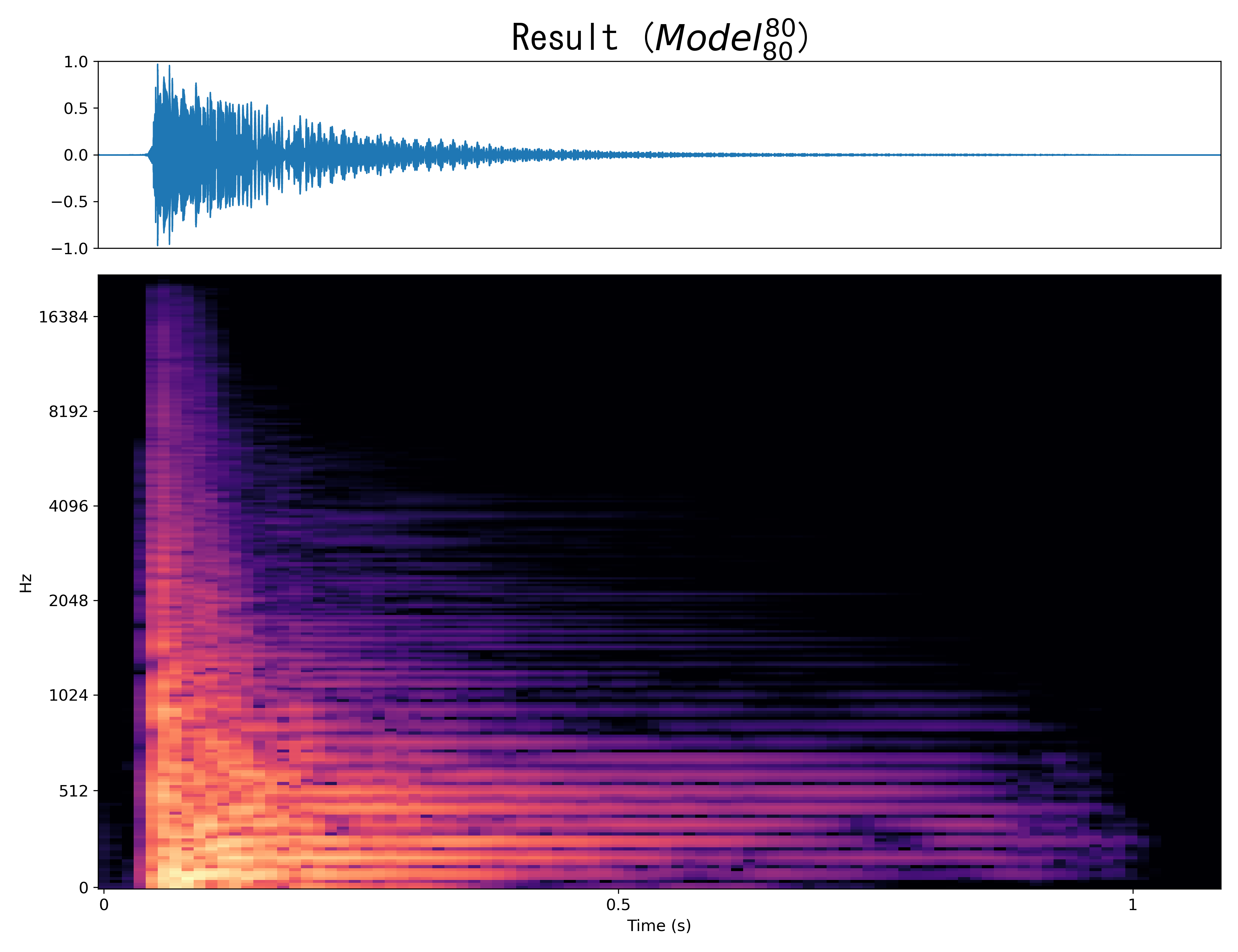
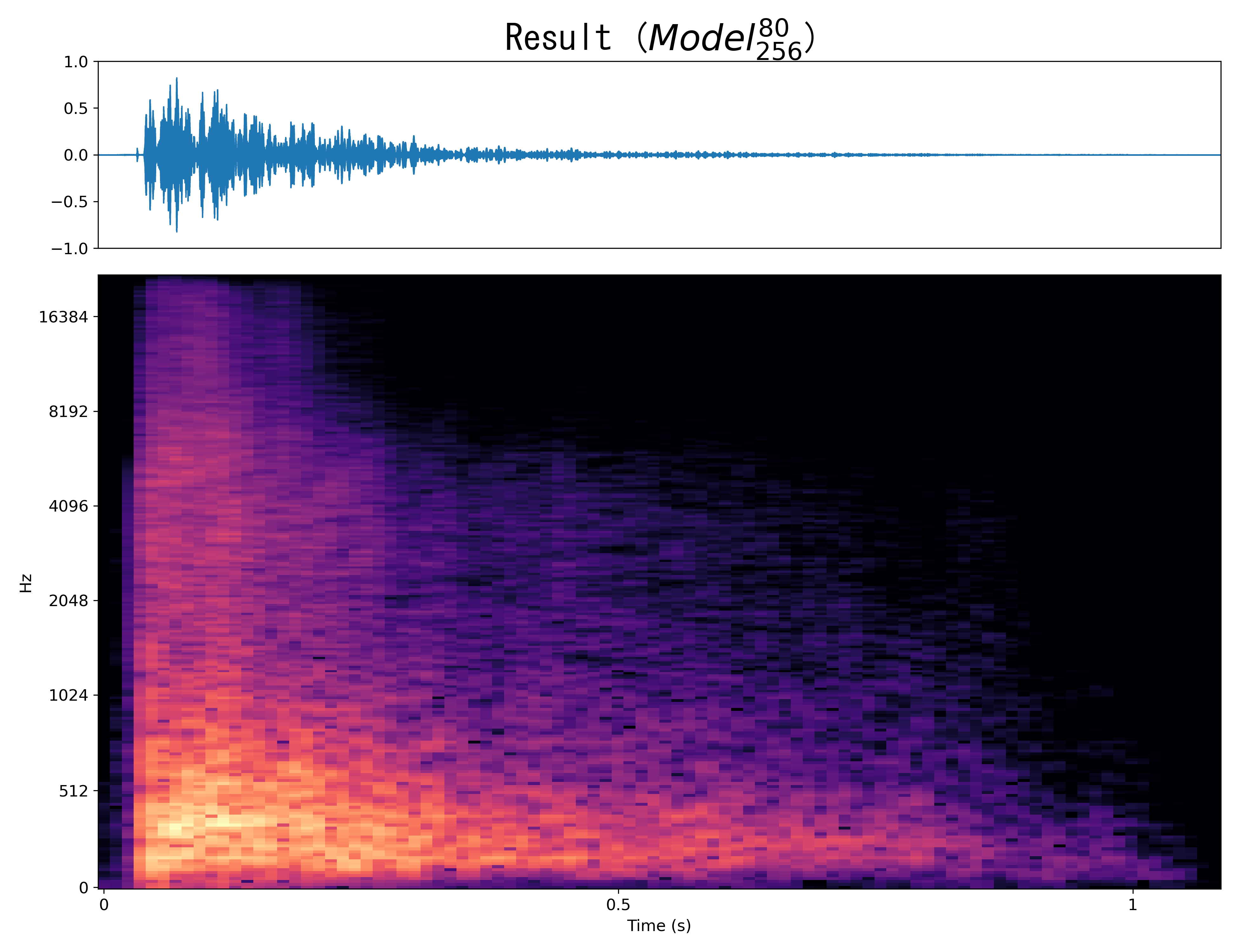
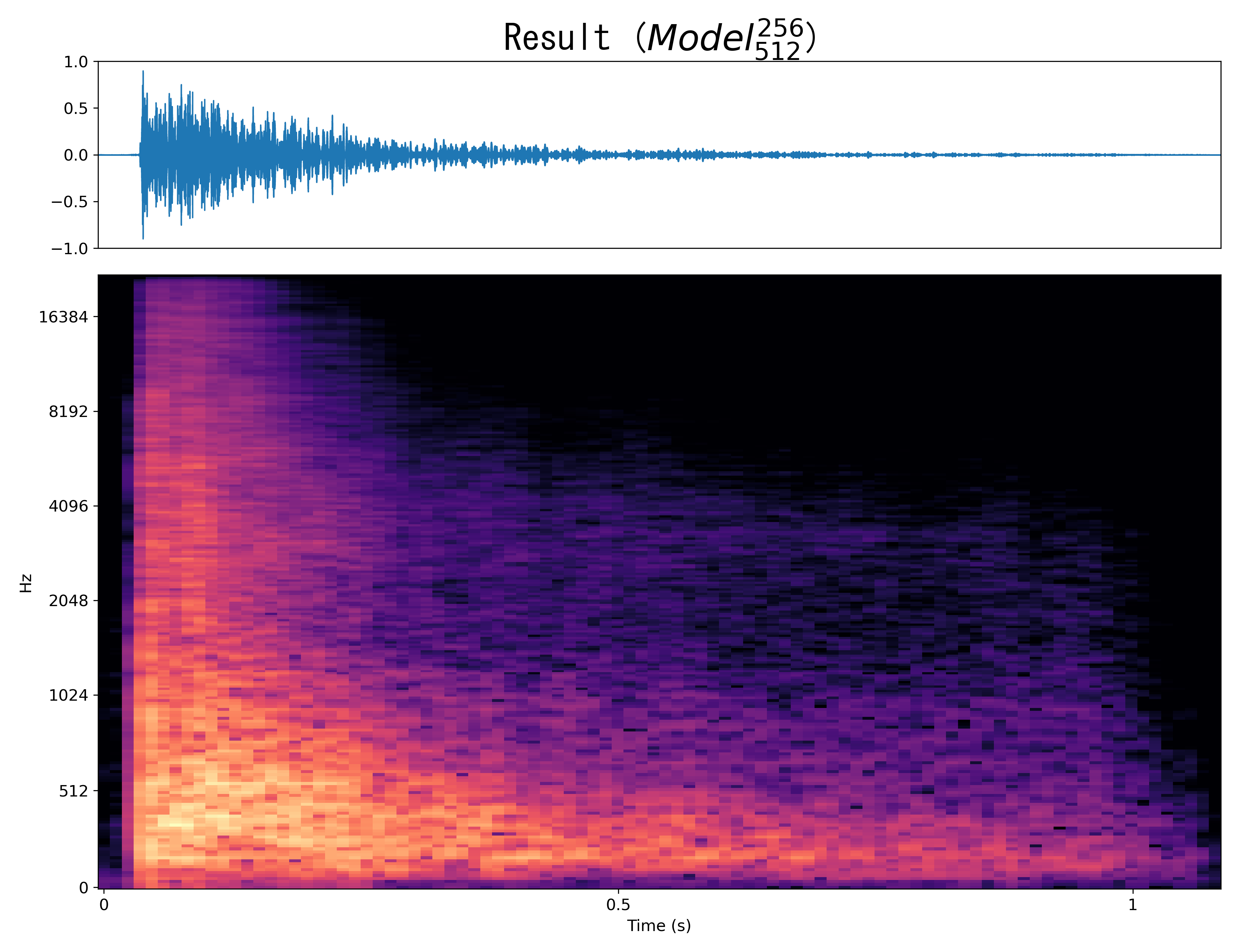
Result10
Mel-spec |
 |
 |
 |
 |
|---|---|---|---|---|